МОТП, Контрольная 2013
Материал из eSyr's wiki.
(→Задача 5) |
(→Решение) |
||
| Строка 262: | Строка 262: | ||
Получаем линейную регрессию: <math> Y = 0.479 + 0.57X </math> | Получаем линейную регрессию: <math> Y = 0.479 + 0.57X </math> | ||
| + | |||
| + | == Задача 6 == | ||
| + | |||
| + | Заданы таблицы значений бинарных признаков для классов <math>K_1</math> и <math>K_2</math>. Требуется найти все тупиковые тесты минимальной длины, а также указать для каждого класса по одному представительному набору, который не совпадает по признакам с тупиковым тестом. | ||
| + | |||
| + | {| border = 1 | ||
| + | |colspan="4" | Класс 1 | ||
| + | |- | ||
| + | | X_1 || X_2 || X_3 || X_4 | ||
| + | |- | ||
| + | | 0 || 0 || 0 || 0 | ||
| + | |- | ||
| + | | 1 || 0 || 1 || 0 | ||
| + | |- | ||
| + | | 0 || 0 || 0 || 1 | ||
| + | |} | ||
| + | |||
| + | {| border = 1 | ||
| + | |colspan="4" | Класс 2 | ||
| + | |- | ||
| + | | X_1 || X_2 || X_3 || X_4 | ||
| + | |- | ||
| + | | 1 || 0 || 1 || 1 | ||
| + | |- | ||
| + | | 1 || 1 || 0 || 0 | ||
| + | |- | ||
| + | | 1 || 1 || 0 || 0 | ||
| + | |} | ||
| + | |||
| + | === Решение === | ||
| + | |||
| + | Кратчайший тупиковый тест состоит из трёх столбцов: <math> (X_1, X_2, X_4), (X_1, X_3, X_4) </math> или <math> (X_2, X_3, X_4) </math> | ||
| + | |||
| + | Представительный набор определяется для класса и для элемента. Например, для первого элемента первого класса представительным будет набор - <math>(X_1, X_2)</math>, а для первого элемента второго класса - набор <math>(X_3, X_4)</math> | ||
| + | |||
{{Курс МОТП}} | {{Курс МОТП}} | ||
Версия 19:54, 23 апреля 2013
Содержание |
Задача 1
Рассматривается задача классификации объектов на два класса по одному признаку. Предполагается, что значение признака x для объектов из классов K1, K2 распределено по закону Рэлея:
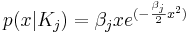
Пусть β1 = 7.3 β2 = 1.3. Требуется найти области значений признака x, соответствующие отнесению объектов в каждый из двух классов байесовским классификатором, если априорные вероятности классов равны, соответственно, 0.3 и 0.7.
Решение
По определению баесовского классификатора:
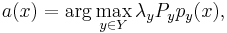
где x - классифицируемый пример, a(x) - классификатор, Y - множество классов (K1,K2), λy - цена ошибки (λ1 = λ2), Py - вероятность появления объекта класса y (априорная вероятность), py(x) - плотность распределения класса y в точке x.
Построим множество, на котором 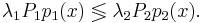 Для этого решим уравнение:
Для этого решим уравнение:
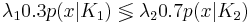
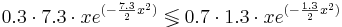
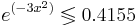
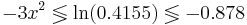
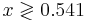
Таким образом, при x > 0.541 классификатор отнесёт объект в класс K2, при x < 0.541 - в класс K1
![]()
Задача 2
Имеется задача распознавания с 4-мя классами и одним признаком. Предполагается, что с использованием метода "Линейная машина" для каждого класса найдены следующие линейные разделяющие функции:
f1(x) = 4.8 − 2.3x
f2(x) = − 4.6 − 2.6x
f3(x) = 4.5 − 2.3x
f4(x) = 4.2 − 0.4x
Требуется изобразить на графике области, соответствующие отнесению к каждому из четырех классов.
Решение
Для нахождения требуемых областей, решим системы неравенств:
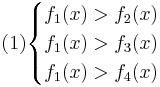
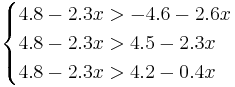
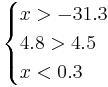
Таким образом, объект будет отнесён в класс 1 при 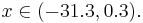
Аналогично:
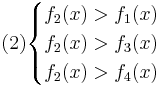
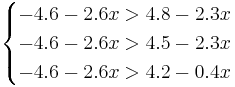
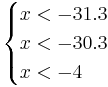
Oбъект будет отнесён в класс 2 при 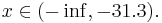
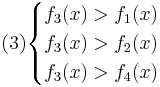
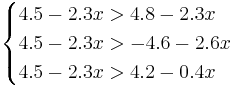
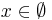 , поэтому никакой объект не будет отнесён к классу 3.
, поэтому никакой объект не будет отнесён к классу 3.
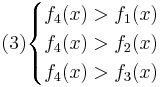
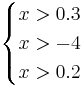
Oбъект будет отнесён в класс 4 при 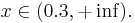
![]()
Задача 3
Предполагается, что линейный дискриминант Фишера используется для распознавания объектов из двух классов по паре признаков x1 и x2. Требуется вычислить вектор, задающий направление перпендикуляра к прямой, разделяющей объекты двух классов:
Класс 1: 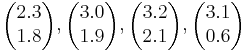
Класс 2: 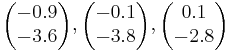
Решение
Перпендикуляр к прямой, разделяющей объекты двух классов, описывается уравнением:
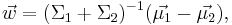
где 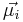 - матожидания объектов каждого класса, а Σi - ковариационная матрица.
- матожидания объектов каждого класса, а Σi - ковариационная матрица.
Посчитаем матождиания:
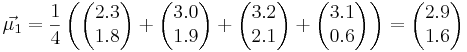
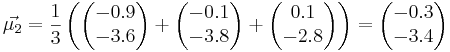
Посчитаем ковариационные матрицы:
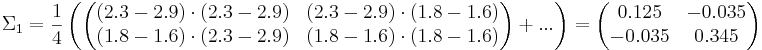
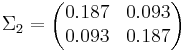
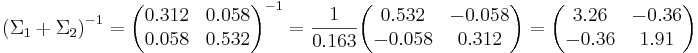
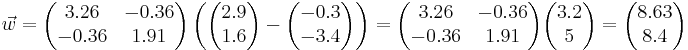

Ответ: 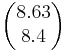
Задача 4
При проведении выборов на ряде избирательных участков производятся фальсификации результатов голосования. Посылка наблюдателя на такой участок предотвращает фальсификации. Пусть известно несколько точек ROC-кривой для метода идентификации "грязных" участков. Требуется определить оптимальную стратегию распределения наблюдателей по участкам и максимальный выигрыш относительно стратегии равномерного распределения по участкам, если всего участков 1000, наблюдателей --- 200 и доля "грязных" участков --- 30%. При этом под оптимальностью понимается максимизация количества честных участков.
| Чувствительность | Ложная тревога |
| 0.86 | 0.11 |
| 0.90 | 0.31 |
| 0.92 | 0.32 |
Решение:
Чувствительность - отношение числа верно распознаных примеров позитивного класса к общему размеру класса: 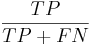
Ложная тревога - отношение числа ошибочно распознанных примеров позитивного класса к размеру негативного класса: 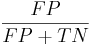
Позитивный исход - идентификация "грязного" участка.
В случае стратегии равномерного распределения наблюдателей по всем участкам, на выбранном участке будет наблюдатель с вероятностью 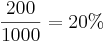 . Всего чистых участков:
. Всего чистых участков: 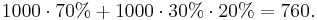
Рассмотрим первый алгоритм.
300 = TP + FN
700 = TN + FP
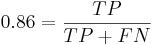
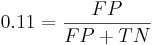
Решая систему, получаем, что TP = 258, FP = 77, FN = 42, TN = 623. Всего метод возвращает 258+77 = 335 результатов. Наблюдателей в распоряжении - меньше, поэтому распределим их равномерно среди участков, которые вернул метод. Вероятность того, что наблюдатель попадёт на произвольны среди выбранных классификатором участков, равна 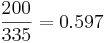 , поэтому среди выбранных участков наблюдатели попадут в среднем на
, поэтому среди выбранных участков наблюдатели попадут в среднем на 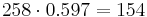 участка, и всего чистыми будут 700 + 154 = 854 участка. Выигрыш составил 854 − 760 = 94 участка.
участка, и всего чистыми будут 700 + 154 = 854 участка. Выигрыш составил 854 − 760 = 94 участка.
Аналогично для других точек.
Задача 5
Задана таблица совместных значений прогнозируемой переменной Y и объясняющей переменной X. Требуется вычислить ковариацию между Y и X, коэффициент корреляции между Y и X, коэффициенты одномерной линейной регрессии.
| Y | 5.9 | 4.0 | 2.4 | 1.7 |
| X | 8.3 | 7.6 | 3.0 | 2.3 |
Решение
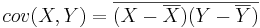
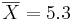
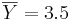
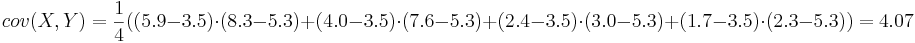
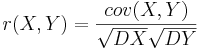
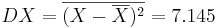
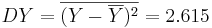
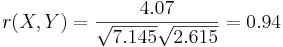
Воспользуемся методом наименьших квадратов для расчета коэффициентов одномерной линейной регрессии Y = a + bX:
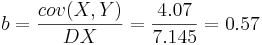
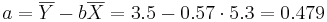
Получаем линейную регрессию: Y = 0.479 + 0.57X
Задача 6
Заданы таблицы значений бинарных признаков для классов K1 и K2. Требуется найти все тупиковые тесты минимальной длины, а также указать для каждого класса по одному представительному набору, который не совпадает по признакам с тупиковым тестом.
| Класс 1 | |||
| X_1 | X_2 | X_3 | X_4 |
| 0 | 0 | 0 | 0 |
| 1 | 0 | 1 | 0 |
| 0 | 0 | 0 | 1 |
| Класс 2 | |||
| X_1 | X_2 | X_3 | X_4 |
| 1 | 0 | 1 | 1 |
| 1 | 1 | 0 | 0 |
| 1 | 1 | 0 | 0 |
Решение
Кратчайший тупиковый тест состоит из трёх столбцов: (X1,X2,X4),(X1,X3,X4) или (X2,X3,X4)
Представительный набор определяется для класса и для элемента. Например, для первого элемента первого класса представительным будет набор - (X1,X2), а для первого элемента второго класса - набор (X3,X4)
Математические основы теории прогнозирования
Материалы по курсу
Билеты (2009) | Примеры задач (2009) | Примеры задач контрольной работы (2013) | Определения из теории вероятностей


