МФСП, 03 лекция (от 17 сентября)
Материал из eSyr's wiki.
Корректность программ
Тема сегодняшней лекции: определение корректной программы и рассмотрение двух методов, которые призваны выдавать программы, корректные по построению
Два метода: VDM и RAISE (этому методу посвящена 6 глава)
Что мы ожидаем от методов построения программ:
- Он должен быть… это может быть максималистское требование… не все из них выполняются на 100 процентов… применим на практике. Понятно, что классов задач много разных, и если он применим к данному классу, то не факт, что применим к другому
- Строгий. Что это означает? Можно достаточно чётко сформулировать границы его применения, и в зависимости от того, какая задача стоит, ответить, имеет смысл применять метод или нет. Во-вторых, те гарантии, которые метод предоставляет, должны выглядеть достаточно убедительно — не общие утверждения
- Должен быть достаточно технологичным. Вот зубы лечат — это технология? Да, во всём мире учат именно технологии, есть чёткий регламент, чёткая последовательность, что надо сделать. Если врач выходит за рамки технологической цепочки, его почти всегда тут же застрахуют и, может быть, лишат лицензии. Сначала анализ, потом осмотр и так далее. Всё расписано достаточно подробно, и любого студента медицинского вуза каждому шагу в этой технологии можно обучить.
Вопрос: чем отличается от методики:
Методика — вещь более размытая. Например, есть методика взятия интегралов? Вообще, есть, вас ей учили на первых курсах.
Больше у лектора общих требований нет, и в реальной жизни методологий по построению программ, отвечающих всем трём позициям, нет. И то, что мы будем рассматривать, достаточно общие решения, но не нужно ждать от них фантастических результатов.
VDM. Откуда растут корни?
Середина 60х годов. Примерно этот период. IBM объявило и появились первые серии Series 360. Это был первый масштабный проект, где объявлялась унифицированная серия машин с унифицированным набором команд. За счёт унификации, с одной стороны, выходила огромная экономия, с другой стороны, требования ко всему были очень высокие, так же как и требования к компилятору. Вместо всех языков программирования тогда были Fortran, Cobol, Assembler. Вместо этой тройки был предложен PL/1. но должен был изменить собой вообще всё. То есть, ПО это ОС, компилятор и набор ПО, если нужно. И хотелось разр. этот самый главный в мире язык программирования т.к, чтобы он был правильный. ни не поленились и организовали лабораторию в Вене (?? V). Они изобрели VDL, Vienna Definition Language, на этом языке написали PL/1 и это описание вложили в компилятор. Это описание был сделано, опубликовано. Не полностью, примерно 95%. После этого творческому коллективу дали паузу, на пересмотр творческого решения и проблемы, и они предложили VDM, Vienna Developer Method. Когда разработали VDL, на технологичность не обращали внимания. Если написан язык и систем команд компьютера, то теоретически можно на вход программе их подать и получить на выходе компилятор. Эта задача есть и сейчас, но в таком максимальном варианте не решается, но есть и сейчас. И тогда считалось, что программисты, делающие компиляторы, исчезнут, он будет генерироваться, потом, когда делали VDM, поняли, что от них никуда не денешься, надо лишь обеспечить методическую поддержку. ...
А вот RAISE появился, это уже где-то появился в 1985, первое серьёзне описание 1990, тогда же RSL, а первое серьёзное описание RAISE в публикациях 1993—95 годов. Понятно, что за эти 20—30 лет они постарались учесть ограничения подхода.
В рамках VDM естественно задумались о строгости, и перед тем как начинать анализ, корректна или некорректна программа, надо дать определение корректности. Есть идеи, какую программу можно назвать корректной? Если мат. модель создана, то считаем, что она сама по себе строгая, и корректность, её определение распределение на две части: дать матем. модель, и должен быть механизм для того, чтобы проверить, удовлетворяет ли реализация тем требованиям, которые сформулированы в модели.
Рассмотрим пример.
Мы уже не раз проходили, как устроена ОС, знаем, что процессы переходят из одних состояний в другие: например, iowait, пассивные. Это достаточно формальное определение, конечный автомат, и будем считать, что больше ничего нет. Микроядерная ОС (mm и pm) --- порядка 10 строчек на С. Как проверить соответствие?
Например, проверить все переходы и состояния. Да, но этот подход недостаточно технологичный. Хотелось бы некое общее состояние получить.
Лектор не на 100% уверен, ...
Общий подход следующий: мы разделяем два мира: мир моделей и реализаций. В модели и реализации, и там и там, есть своё пространство составляющих. Для простоты будем считать, что есть операции, функции, и данные берутся из входного пространства данных и данные генерируются в выходное пространство данных. Эти пространства разные. И в случае модели есть такая структура данных, пис. конечный автомат. В программе реализации такой может не быть. Там могут быть структуры существенно более богатые. И имеются операции. И тогда для проверки корректности рисуется такая диаграмма: имеется некоторое состояние, и мы в этом состоянии i_мдель? мы применяем к нему переход f_модель и получаем результат j_model. И можем сделать соответствие i_impl →(f_impl) j_impl. Заметьте, что, собственно, входные данные не просто разные, но и в разных пространствах лежат. Между ними надо и можно установить соответствие. Соответствие устанавливается в эту сторону. Это некое отображение от сложного к простому. Часто это отображение называют абстракцией. Более принятое название — функция retrieve, retr. Кротко и красиво что можно сказать: реализация корректна в том и только в том случае, если диаграмма коммутативна.
Эта функция необязательно должна быть тотальная, у неё есть что-то типа предусловия. Это отображение (f) определено, когда некое предусловие удовлетворяется. Заметьте, что в реализации пространстве оно тоже может быть. И это должно быть согласовано.
Для любого i в реализ. пространстве, если его retr удовлетворяет предусловию, то и оно сам должно ему удовлетворять.
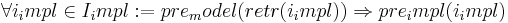
Почему не выполняется в другую сторону: пример с логарифмом
Этот подход в общем смысле формален, тк: предусловие может слаб. модель. По поводу постусловия обратня ситуация.
По поводу результирующих функций
Это хорошая самостоятельная работа.
Сейчас мы заканчиваем с VDM, после этого перейдём к RAISE.
Что реально нужно делать, чтобы доказывать корректность программ: RAISE очень похож н VDM. cGTW/ JGBC/ HTKMYSV ,HPV? или имплицивным. Retr пред. как обычная функция, и потом прост нужно уметь доказывать, что два retr выполняются.
Был выдвинут тезис, что модель и retr должны быть адекватны, и это правильно. Но с другой стороны, если модель большая, то приходится сильнее абстрагироваться.
Основная сложность --- в функции retr. Сложность retr фактически сложность реализации. Поэтому подход другой: строится цепочка моделей. Для компиляторов было порядка 5 или 6 этапов.
При помощи VDM верифицировали компилятор Ada.
Многие противники подхода говорили: вместо того, чтобы сделать работу честно и правильно 1 раз, необходимо сделать её несколько раз, провести работу по доказательству (которая очень трудоёмкая). Но опыт показал, что на компиляторах сроки разработки удаётся сократить и удаётся предъявить корректную программу с первого предъявления.
Товарищи, которые рзр VDM... КФШЫУ рсшифровывается как строгий подход к программнй инженерии. Чтбы этим треб. удовл., смую слжную технлогическую деталь в техзнлогии VDM решили убрть --- retr. Чем retr был хрош? Можно было изменять сигнатуру функции. VDM всё это рзрешал, а RAISE зпретил. что осталось? остался подход пошговой детализации. Поскльку retr убрли, то сигнатуры модели и реализ. совп., структуры днных по сущ. одни и те же, тк что всё сильно упростилось, но при этом raise отошёл н ещё дин шг нзд. Что было в VDM? Пусть в VDM первя модель --- эксплицитня функция. При этом структуры данных должны быть описаны и заданы. В случае с нашим конечным автматом рзр. мжет уже задумться, как хранить сост. Разр. сказли, чт на первом этапе мдкель должна быть предельно абстрактной. Функции есть, структур нет. И этот способ опис. повед. системы, когж сигн. опер. задаются, стр. не задаются, нзыва. аксиоматич. или алгеб. специф. Есть тонксти в трактовке (кс и алг), но для нас разницы нет. В RAISE были введены аксиомы и при помощи них это опис.
И при пмощи RAISe может расп. дст. детальн:
Из чего состоит технология RAISE: пис. модель нулевого уровня. Что должно быть задано?
0.1 Определяются некие типы данных. Не писываются, а просто бъявляются. 0.2 Описываются сигн. операций (функций). Это зн, ао-первых, здаётся имя функции и перечисл. типы операндов и результата (вхдных и выходных данных) 0.2.1 С точки зрения RAISE, константы это ткая функция без значений Они указ., что функция тотальна, детерм. и терминирующ. Если функция нетотальная, то надо писать тильду. На урвне сигн. в чём нетотальность опр. нельзя, ндо см. сигнтуру 0.3 Аксиомы.
Следующий шаг
1.1 Типы данных мжно пополнить. 1.2 Можно пополнить набор функций. 1.3 Можно пополнить набор аксиом. Но все старые аксимы сохр. 1.4 Докзательство сглсованнсти.
Модели 0 и 1 уровня должны быть согласованы. Как это делается. Согласованнсть с пзиции RSL NTHVBY YTAHVKMYSQ, а технология RAISE ... расматривается отношение утчнения, дн мдель мдет уточн. другую, имы можем считать чт мдель 1 уточняет модель 0, если одн утчн. другую. И уточн., если всё схр. и добавлено тлько новое, и есть один ньнс, связанный с уточнением самих типов данных. До этго типы данных были предст. только именами, по мере того, как априбл. к релизации, мы в какой-то момент, не бяз. для всех типов одновр., должны эти типы определить (списки, деревья....) перехд т бъявл. к пределнию можно делать дв раза, не более чем. Первый раз — берётся и пис. реальная структура (например T3 — нат. число или T4 --- список нат. чисел). Мгу уточнить (T4 --- конечный списко нат. чисел). Это первое уточн. типа. Второй вид: для каждй стр. данных форм. определяется т. н. максимальный тип. Эт некий тип., пр. природу. Для булевских чисел мкс. типов вл. сами булевские числа. Для нт --- целые. Для конечных тсписков, мнжеств, тобр --- беск. Если есть список нт. чисел, то вопрос, что будет макс. тиипом стр. данных, гр. список нат. чисел.? Беск. списк целых чисел. Такое уточнение --- максимизция --- тоже првильное уточнение. Саме глвное, чт нужно доказать --- все аксиомы схраняются.
Техника доказательства достаточно простая и чевидня, как правило, пдставновка. Дост.ю просто делать, если была аксим. специф, а в модели 1 написали определение. Помимо подст. исп. библ. правил вывда, а она связ. с териями, пстр. для типовых структур данных. Например: в случае мн-в в теории сказано, что x ∈ {} всегда тождественно равно false. И при помощи псл. упрощения длжны прийти к тому, что либо все аксиомы тожд. true, либо где-то не true, и вы дказали, чт новя спец. не явл. строгим уточн. исходной. В этом и состоит метод.
Пример: полностью пример имеется в мет. пособии.
Имеется схем, пис. БД
scheme DATABASE =
class type Database, Key, Data
value empty : Database,
insert : Key × Database → Database
remove : Key × Database → Database
defined : Key × Database → Bool
lookup : Key × Database → Data
axiom ∀ k : Key: - defined(K, empty) = false
Других ксим рассм. не будем.
Эт нулевй ур. спец. н первм. обязны пост. все спец. сигн, но БД, например, будет уточнена
type Database = (Key × Data) - set
value empty : Database = {}
defined : Ket × Database → Bool
defined()k,db = ∃ d : Data :- (k, d) ∈ db)
Проверяем. Все типы данных определены, все сигнатуры пр. Для одного типа данных сказали, что это мн-во пар, и для двух функций сказали, чт empty всегда даёт пустое мнжеств, и функция defined пределена таким утверждением. Этого дост., чтбы рассуждть о сохр. или несхр. аксиомы. Для того, чтобы это делать, есть некая техника. В простом ... мы просто раскрывем все кванторы.
Раскрываем ∀, defined, empty, птом раскр. квантор сущ. и мы прихдим к нек. выражению: (k, d) ∈ {}. Мы знаем, чт эт false, эт озн., чт левая часть тжд. false, знчит, аксиома тжд. true. Вот мы провели док-во, что первая аксиома сохранилась.
Практик-еор сообр: как в общем случе проверять? общего ответа нет. Какие вообще спец. включать, а какие нет? В общем случе ответа на этт вопр. нет. Практ. подхдо такой: в наших функциях мы делаем перве грубе разд: какие функции сзд. нвые данные в нашей системе (тут мы уже рзделяем целевые объекты и вспомгтельные). Те опер, где мы плуч. новое сост. БД, это т. н. функции-генерторы, генераторы новых знач. целевого типа. Те функции, которые пзв. ущнать толдько некоторые характеристики, эт некие обсерверы, которые опзв. что-то узнать (напр, lookup). Эти функции на сост. БД не влияют. И есть ещё более тнкое деление: функция remove. Любое зн. Database мно постр. при помощи цеп. инсертов, и для геенрции всех зн. БД куьщму не нужна, а а в реальной жизни нужна и в модели должна присут. Эти функции, которые несут некоторую избыточность, их называют трансформерами или модификаторами. Они меняют состояние, но они привдят к сост, к кторым можно без них перейти.
В число ксиом системы бычно включ. аксиомы, опис. генераторы и обсерверы. А псле того, как трботал генертр или трансформер, как изменилсь повед системы? А эт даёт обсервера. И если для комб. ген. и обс. есть опис. поведение, то эт даёт эффект генертора. Т. о., мы должны согл. с лектором, это саме абс. опис. системы, которое может быть.
Теперь грустном: на экз. будет задача, на к-рй небх. будет доказать правильности или неправильность уточнения.
По поводу реальной жизни: никаие пдобные системы аналит. не закаываются, н отедьные пдсистемы техн. доказ, исп. в raise, также исп. Темтика становится всё блее востр.
Формальная спецификация и верификация программ
|
|


