МОТП, Билеты (2009)
Материал из eSyr's wiki.
(→Недостатки метода главных компонент. Метод независимых компонент.) |
|||
| (61 промежуточная версия не показана) | |||
| Строка 1: | Строка 1: | ||
= Часть 1 (Ветров) = | = Часть 1 (Ветров) = | ||
| - | == Метод максимального правдоподобия. Его достоинства и недостатки | + | == Метод максимального правдоподобия. Его достоинства и недостатки == |
| - | * [http://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D0%BE%D0%B4_%D0%BC%D0%B0%D0%BA%D1%81%D0%B8%D0%BC%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D0%B3%D0%BE_%D0%BF%D1%80%D0%B0%D0%B2%D0%B4%D0%BE%D0%BF%D0%BE%D0%B4%D0%BE%D0%B1%D0%B8%D1%8F | + | * [http://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D0%BE%D0%B4_%D0%BC%D0%B0%D0%BA%D1%81%D0%B8%D0%BC%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D0%B3%D0%BE_%D0%BF%D1%80%D0%B0%D0%B2%D0%B4%D0%BE%D0%BF%D0%BE%D0%B4%D0%BE%D0%B1%D0%B8%D1%8F ru.wiki:Метод максимального правдоподобия] |
| - | * [http://www.nsu.ru/mmf/tvims/chernova/ms/lec/node14.html | + | * [http://www.nsu.ru/mmf/tvims/chernova/ms/lec/node14.html Метод макс. правдоподобия по Черновой из НГУ] |
| - | ''' Метод максимального правдоподобия ''' | + | <div class="definition">''' Метод максимального правдоподобия ''' — метод оценивания неизвестного параметра путём максимизации функции правдоподобия: <math>f_x (x|\theta) = \prod_{i=1}^n f_x(x_i | \theta)</math> для независимой выборки n величин.</div> |
| - | + | '''Недостатки:''' | |
| - | + | ||
* нужно знать априорное распределение (с точностью до параметров) наблюдаемой величины | * нужно знать априорное распределение (с точностью до параметров) наблюдаемой величины | ||
* хорошо применим при допущении, что <math>n \rightarrow \infty </math> (асимптотически оптимален), что в реальности не так | * хорошо применим при допущении, что <math>n \rightarrow \infty </math> (асимптотически оптимален), что в реальности не так | ||
* проблема выбора структурных параметров, позволяющих избегать переобучения (проблема вообще всех методов машинного обучения) | * проблема выбора структурных параметров, позволяющих избегать переобучения (проблема вообще всех методов машинного обучения) | ||
| - | * необходима [http://ru.wikipedia.org/wiki/Регуляризация_(математика) регуляризация] | + | * необходима [http://ru.wikipedia.org/wiki/Регуляризация_(математика) регуляризация] метода |
| - | ==Решение несовместных СЛАУ | + | == Решение несовместных СЛАУ == |
В статистике, машинном обучении и теории обратных задач под регуляризацией понимают добавление некоторой дополнительной информации к условию с целью решить некорректно поставленную задачу или предотвратить переобучение. | В статистике, машинном обучении и теории обратных задач под регуляризацией понимают добавление некоторой дополнительной информации к условию с целью решить некорректно поставленную задачу или предотвратить переобучение. | ||
| - | '''Несовместная СЛАУ''' | + | <div class="definition">'''Несовместная СЛАУ''' — система линейных уравнений, не имеющая ни одного решения.</div> |
| - | '''Совместная СЛАУ''' | + | <div class="definition">'''Совместная СЛАУ''' — система линейных уравнений, имеющая хотя бы одно решение.</div> |
| - | ''' Ридж-регуляризация''' (ридж-регрессия, [http://en.wikipedia.org/wiki/Tikhonov_regularization регуляризация Тихонова]) матрицы <math>A^T A</math> | + | <div class="definition">''' Ридж-регуляризация''' (ридж-регрессия, [http://en.wikipedia.org/wiki/Tikhonov_regularization регуляризация Тихонова]) матрицы <math>A^T A</math> — матрица <math>A^T A + \lambda I</math>, где <math>\lambda</math> — коэффициент регуляризации. Всегда невырождена при <math>\lambda > 0</math>.</div> |
| - | ''' Нормальное псевдорешение ''' СЛАУ <math>Ax = b</math> | + | <div class="definition">''' Нормальное псевдорешение ''' СЛАУ <math>Ax = b</math> — вектор <math> x = (A^T A + \lambda I )^{-1} A^T b </math>. |
* всегда единственно | * всегда единственно | ||
* при небольших <math>\lambda</math> определяет псевдорешение с наименьшей нормой | * при небольших <math>\lambda</math> определяет псевдорешение с наименьшей нормой | ||
* любое псевдорешение имеет минимальную невязку | * любое псевдорешение имеет минимальную невязку | ||
| + | </div> | ||
| - | == Задача восстановления линейной регрессии. Метод наименьших квадратов | + | == Задача восстановления линейной регрессии. Метод наименьших квадратов == |
* [http://www.nsu.ru/mmf/tvims/chernova/ms/lec/node60.html лекции Черновой из НГУ] | * [http://www.nsu.ru/mmf/tvims/chernova/ms/lec/node60.html лекции Черновой из НГУ] | ||
| - | * [http://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%B3%D1%80%D0%B5%D1%81%D1%81%D0%B8%D0%BE%D0%BD%D0%BD%D1%8B%D0%B9_%D0%B0%D0%BD%D0%B0%D0%BB%D0%B8%D0%B7 | + | * [http://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%B3%D1%80%D0%B5%D1%81%D1%81%D0%B8%D0%BE%D0%BD%D0%BD%D1%8B%D0%B9_%D0%B0%D0%BD%D0%B0%D0%BB%D0%B8%D0%B7 ru.wiki:Регрессионный анализ] |
| - | '''Задача регрессионного анализа (неформально)'''. | + | '''Задача регрессионного анализа (неформально)''': предположим, имеется зависимость между неизвестной нам случайно величиной ''X'' (мы судим о ней по наблюдаемым признакам, т.е. по случайной выборке) и некоторой переменной (параметром) ''t''. |
| - | + | <div class="definition">'''Задача регрессионного анализа''' — определение наличия и характера (математического уравнения, описывающего зависимость) связи между переменными. В случае линейной регрессии, зависимость ''X'' от параметра ''t'' проявляется в изменении средних значений ''Y'' при изменении ''t'' (хотя при каждом фиксированном значении ''t'' величина ''X'' остается случайной величиной).</div> | |
| - | ''' | + | Искомая зависимость среднего значения ''X'' от значений ''Z'' обозначается через функцию ''f''(''t''): <math>E(X | Z = t)=f(t)</math>. Проводя серии экспериментов, требуется по значениям ''t''<sub>1</sub>, …, ''t''<sub>''n''</sub> и ''X''<sub>1</sub>, …, ''X''<sub>''n''</sub> оценить как можно точнее функцию ''f''(''t''). |
| - | + | Однако, наиболее простой и изученной является линейная регрессия, в которой неизвестные настраиваемые параметры (''w''<sub>''j''</sub>) входят в решающее правило '''линейно''' с коэффициентами <math>\psi_j(x)</math>: <math>y(x,w)=\sum_{j=1}^m w_j \psi_j(x)=w^T \psi(x)</math>/ | |
| - | + | '''Пример''' (''простой пример на пальцах''): [http://en.wikipedia.org/wiki/Linear_Regression#Example Linear Regression Example]. | |
| - | + | ||
| - | '''Пример''' (''простой пример на пальцах''): [http://en.wikipedia.org/wiki/Linear_Regression#Example Linear Regression Example] | + | |
<math>S(t, \hat{t})</math> — функция потерь от ошибки. ''На пальцах: берем найденную путем регрессии функцию <math>\hat{t}(x)</math> и сравниваем её выдачу на тех же наборах <math>x</math>, что и заданные результаты эксперимента <math>t(x)</math>.'' | <math>S(t, \hat{t})</math> — функция потерь от ошибки. ''На пальцах: берем найденную путем регрессии функцию <math>\hat{t}(x)</math> и сравниваем её выдачу на тех же наборах <math>x</math>, что и заданные результаты эксперимента <math>t(x)</math>.'' | ||
* <math>S_1(t, \hat{t}) = (t - \hat{t})^2</math> | * <math>S_1(t, \hat{t}) = (t - \hat{t})^2</math> | ||
| - | * <math>S_2(t, \hat{t}) = |t - \hat{t}| | + | * <math>S_2(t, \hat{t}) = |t - \hat{t}|</math> |
* <math>S_3(t, \hat{t}) = \delta^{-1}(t - \hat{t})</math> | * <math>S_3(t, \hat{t}) = \delta^{-1}(t - \hat{t})</math> | ||
| - | Основная задача — минимизировать эту функцию, что значит минимизировать <math>\mathbb{E} S(t, \hat{t}(x,w)) = \int\int S(t, \hat{t}(x,w)) p(x,t) dx dt \rightarrow \min_{w}</math> | + | Основная задача — минимизировать эту функцию, что значит минимизировать <math>\mathbb{E} S(t, \hat{t}(x,w)) = \int\int S(t, \hat{t}(x,w)) p(x,t) dx dt \rightarrow \min_{w}</math>. |
---- | ---- | ||
| - | ''' Метод наименьших квадратов ''' — минимизация функции потери ошибки <math>S(t, \hat{t}) = (t - \hat{t})^2</math> | + | <div class="definition">''' Метод наименьших квадратов ''' — минимизация функции потери ошибки <math>S(t, \hat{t}) = (t - \hat{t})^2</math>.</div> |
| - | + | '''Особенности квадратичной функции потерь:''' | |
| - | * | + | * ''Достоинтсва'': |
| - | ** | + | ** Гладкая (непрерывная и дифференцируемая); |
| - | ** | + | ** Решение может быть получено в явном виде. |
| - | * | + | * ''Недостатки'': |
| - | ** | + | ** Решение неустойчиво; |
| - | ** | + | ** Не применима к задачам классификации. |
| - | ==Задача восстановления линейной регрессии. Вероятностная постановка | + | == Задача восстановления линейной регрессии. Вероятностная постановка == |
Представим регрессионную переменную как случайную величину с плотностью распределения <math>p(t|x)</math>. | Представим регрессионную переменную как случайную величину с плотностью распределения <math>p(t|x)</math>. | ||
| - | В большинстве случаев предполагается нормальное распределение относительно некоторой точки y(x) : <math>t = y(x) + \varepsilon~;~~\varepsilon \sim N(\varepsilon | 0, \sigma^2)</math>. | + | В большинстве случаев предполагается нормальное распределение относительно некоторой точки ''y''(''x''): <math>t = y(x) + \varepsilon~;~~\varepsilon \sim N(\varepsilon | 0, \sigma^2)</math>. |
| + | Максимизируя правдоподобие (оно задается следующей формулой: <math>p(t|y)=\prod_{i=1}^n \dfrac{1}{\sqrt{2\pi\sigma^2}}\, \exp\left(-\dfrac{(t_i-y_i)^2}{2\sigma^2}\right) \rightarrow \max</math>), получаем эквивалентность данного метода методу наименьших квадратов, т. к. взяв логарифм от формулы выше, получаем: | ||
| + | <math>\sum_{i=1}^n (t_i-y_i)^2 = \sum_{i=1}^n (t_i-w^T \phi (x_i))^2 \rightarrow \min_w</math> | ||
| - | + | == Логистическая регрессия. Вероятностная постановка == | |
| - | + | ||
| - | + | ||
| - | = | + | <div class="definition">''' Логистическая регрессия''' ([http://en.wikipedia.org/wiki/Logistic_regression en-wiki], [http://www.machinelearning.ru/wiki/index.php?title=%D0%9B%D0%BE%D0%B3%D0%B8%D1%81%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B0%D1%8F_%D1%80%D0%B5%D0%B3%D1%80%D0%B5%D1%81%D1%81%D0%B8%D1%8F machinelearning]) — метод [http://ru.wikipedia.org/wiki/Задача_классификации классификации объектов] на два класса, работающий при помощи логистической функции регрессии: <math>p(t|x, w) = \frac{1}{1 + e^{-t y(x)}}</math> ([http://en.wikipedia.org/wiki/Sigmoid_function сигмоид]).</div> |
| - | ''' Логистическая регрессия''' ([http://en.wikipedia.org/wiki/Logistic_regression en-wiki]) — метод [http://ru.wikipedia.org/wiki/Задача_классификации классификации объектов] на два класса, работающий при помощи логистической функции регрессии: <math>p(t|x, w) = \frac{1}{1 + e^{-t y(x)}}</math> ([http://en.wikipedia.org/wiki/Sigmoid_function сигмоид]). | + | |
Эта функция является функцией правдоподобия по w и распределением вероятности по t, т.к. <math>\sum_t p(t|x,w)=1, \ \ p(t|x,w)>0</math>. | Эта функция является функцией правдоподобия по w и распределением вероятности по t, т.к. <math>\sum_t p(t|x,w)=1, \ \ p(t|x,w)>0</math>. | ||
| - | == ЕМ-алгоритм для задачи разделения гауссовской смеси | + | == ЕМ-алгоритм для задачи разделения гауссовской смеси == |
Пусть имеется выборка <math>X \sim \sum_{j=1}^l w_j \mathcal{N} (x | \mu_j , \Sigma_j)</math>, где ''l'' - число компонент смеси. | Пусть имеется выборка <math>X \sim \sum_{j=1}^l w_j \mathcal{N} (x | \mu_j , \Sigma_j)</math>, где ''l'' - число компонент смеси. | ||
| - | + | EM-алгоритм: ([http://en.wikipedia.org/wiki/Expectation-maximization_algorithm en-wiki]], [http://www.machinelearning.ru/wiki/index.php?title=EM_%D0%B0%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_(%D0%BF%D1%80%D0%B8%D0%BC%D0%B5%D1%80) machinelearning-пример]) | |
| - | # | + | # Выбираем начальное приближение для параметров <math>\mu_j, \Sigma_j, w_j, j \isin [1, l]</math>. |
| - | # E-шаг: | + | # E-шаг (expectation): находим для каждого элемента выборки вероятность, с которой он принадлежит каждой из компонент смеси. |
| - | # M-шаг: с учетом вероятностей на предыдущем шаге пересчитываем коэффициенты начального шага | + | # M-шаг (maximization): с учетом вероятностей на предыдущем шаге пересчитываем коэффициенты начального шага. |
| - | # | + | # Переход к E шагу до тех пор, пока не будет достигнута сходимость. |
| - | + | '''Недостатки:''' | |
| - | * ( | + | * (!) Не позволяет определить количество компонент смеси (''l''). |
| - | ** | + | ** Величина ''l'' является структурным параметром. |
| - | * | + | * В зависимости от выбора начального приближения может сходиться к разным точкам. |
| - | * может сваливаться в локальный экстремум | + | * может сваливаться в локальный экстремум. |
| - | ==Основные правила работы с вероятностями. Условная независимость случайных величин | + | == Основные правила работы с вероятностями. Условная независимость случайных величин == |
| - | ''' Случайная величина ''' | + | <div class="definition">''' Случайная величина ''' — это измеримая функция, заданная на каком-либо вероятностном пространстве. ([http://ru.wikipedia.org/wiki/%D0%A1%D0%BB%D1%83%D1%87%D0%B0%D0%B9%D0%BD%D0%B0%D1%8F_%D0%B2%D0%B5%D0%BB%D0%B8%D1%87%D0%B8%D0%BD%D0%B0 ru.wiki])</div> |
| - | ''' Функция распределения ''' <math>F_X(x)</math> | + | <div class="definition">''' Функция распределения ''' <math>F_X(x)</math> — вероятность того, что случайная величина ''X'' меньше ''x'': <math>F_X(x) = \mathbb{P}(X \leqslant x)</math>.</div> |
| - | ''' Плотность вероятности ''': | + | <div class="definition">''' Плотность вероятности ''': |
| - | * | + | * В дискретном случае — вероятность того, что ''X'' = ''x''; |
| - | * | + | * В непрерывном случае — производная функции распределения.</div> |
| - | + | Далее ''X'', ''Y'' — случайные величины с плотностями вероятности <math>p(x), p(y)</math>. | |
| - | Случайные величины X,Y называются независимыми, если <math>p(x,y) = p(x) \cdot p(y)</math> | + | <div class="definition">Случайные величины ''X'', ''Y'' называются '''независимыми''', если <math>p(x,y) = p(x) \cdot p(y)</math>.</div> |
| - | ''' Условная плотность ''' | + | <div class="definition">''' Условная плотность ''' — <math>p(x|y) = \frac{p(x,y)}{p(y)}</math>. |
| - | * в дискретном случае | + | * в дискретном случае — вероятность того, что наступило событие ''x'', при условие наступления события ''y''.</div> |
| - | + | '''Правило суммирования:''' пусть <math>A_1, \dots, A_k</math> — ''k'' взаимоисключающих события, одно из которых обязательно наступает. Тогда | |
* <math>\mathbb{P}(A_i \cup A_j) = \mathbb{P}(A_i) + \mathbb{P}(A_j)</math> | * <math>\mathbb{P}(A_i \cup A_j) = \mathbb{P}(A_i) + \mathbb{P}(A_j)</math> | ||
* <math>\sum_{i=1}^k \mathbb{P}(A_i) = 1</math> | * <math>\sum_{i=1}^k \mathbb{P}(A_i) = 1</math> | ||
| - | * | + | * '''Формула полной вероятности''': <math>\sum_{i=1}^k \mathbb{P}(A_i|B) = 1</math> или <math>P(B)=\sum_{i=1}^k \mathbb{P}(B|A_i) \mathbb{P}(A_i)</math>. |
| + | * В интегральном виде: <math>p(b) =\int p(b,a)da=\int p(b|a)p(a)da</math>. | ||
| + | * '''Формула Байеса''' ([http://ru.wikipedia.org/wiki/Формула_Байеса ru:wiki]): <math>P(A|B) = \frac{P(B | A)\, P(A)}{P(B)}</math>. | ||
Случайные величины называются '''условно независимыми''' от <math>z</math>, если <math>p(x,y|z) = p(x|z)p(y|z)</math> | Случайные величины называются '''условно независимыми''' от <math>z</math>, если <math>p(x,y|z) = p(x|z)p(y|z)</math> | ||
| - | * | + | * Это значит: вся информация о взаимосвязи между <math>x</math> и <math>y</math> содержится в <math>z</math>. |
| - | * | + | * Из безусловной независимости не следует условная независимость. |
| - | * | + | * '''Основное свойство условно независимых величин''': <math>p(z|x,y) = \frac{1}{Z} \cdot \frac{p(z|x) p(z|y)}{p(z)}</math>, где <math>Z = \frac{p(x)p(y)}{p(x,y)}</math><!--в презентациях ошибка, [http://www.cmcspec.ru/ipb/index.php?showtopic=536&view=findpost&p=15899 '''проверено''']-->. |
| - | == Графические модели. Основные задачи, возникающие в анализе графических моделей | + | == Графические модели. Основные задачи, возникающие в анализе графических моделей == |
'''Графическая модель''' -- ориентированный или неориентированный граф, в котором вершины соответствуют переменным, а ребра - вероятностным отношениям, определяющим непосредственные зависимости. | '''Графическая модель''' -- ориентированный или неориентированный граф, в котором вершины соответствуют переменным, а ребра - вероятностным отношениям, определяющим непосредственные зависимости. | ||
| Строка 135: | Строка 134: | ||
==Байесовские сети. Примеры.== | ==Байесовские сети. Примеры.== | ||
| - | [http://ru.wikipedia.org/wiki/%D0%91%D0%B0%D0%B9%D0%B5%D1%81%D0%BE%D0%B2%D1%81%D0%BA%D0%B0%D1%8F_%D1%81%D0%B5%D1%82%D1%8C_%D0%B4%D0%BE%D0%B2%D0%B5%D1%80%D0%B8%D1%8F | + | '''Байесовская сеть''' — это вероятностная модель, представляющая собой множество переменных и их вероятностных зависимостей. |
| + | |||
| + | ([http://ru.wikipedia.org/wiki/%D0%91%D0%B0%D0%B9%D0%B5%D1%81%D0%BE%D0%B2%D1%81%D0%BA%D0%B0%D1%8F_%D1%81%D0%B5%D1%82%D1%8C_%D0%B4%D0%BE%D0%B2%D0%B5%D1%80%D0%B8%D1%8F wiki: опред., принципы и пример]) + '''см. презентации''' | ||
| + | |||
| + | '''Особенности''': | ||
| + | * По смыслу построения байесовские сети не могут содержать ориентированные циклы, т.к. это будет нарушать правило умножения вероятностей | ||
| + | * Главным достоинством графических моделей является относительно простое выделение условно-независимых величин, которое облегчает дальнейший анализ, позволяя значительно уменьшить количество факторов, влияющих на данную переменную | ||
== Марковские сети. Примеры.== | == Марковские сети. Примеры.== | ||
==Скрытые марковские модели. Обучение СММ с учителем.== | ==Скрытые марковские модели. Обучение СММ с учителем.== | ||
* [http://ru.wikipedia.org/wiki/%D0%A1%D0%BA%D1%80%D1%8B%D1%82%D0%B0%D1%8F_%D0%BC%D0%B0%D1%80%D0%BA%D0%BE%D0%B2%D1%81%D0%BA%D0%B0%D1%8F_%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D1%8C На википедии] | * [http://ru.wikipedia.org/wiki/%D0%A1%D0%BA%D1%80%D1%8B%D1%82%D0%B0%D1%8F_%D0%BC%D0%B0%D1%80%D0%BA%D0%BE%D0%B2%D1%81%D0%BA%D0%B0%D1%8F_%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D1%8C На википедии] | ||
| - | * [http://ru.wikibooks.org/wiki/%D0%A1%D0%BA%D1%80%D1%8B%D1%82%D1%8B%D0%B5_%D0%BC%D0%B0%D1%80%D0%BA%D0%BE%D0%B2%D1%81%D0%BA%D0%B8%D0%B5_%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D0%B8 | + | * [http://ru.wikibooks.org/wiki/%D0%A1%D0%BA%D1%80%D1%8B%D1%82%D1%8B%D0%B5_%D0%BC%D0%B0%D1%80%D0%BA%D0%BE%D0%B2%D1%81%D0%BA%D0%B8%D0%B5_%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D0%B8 На викибуки] |
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | <br/> | |
| - | ' | + | '''Скрытая Марковская модель''' (первого порядка) — это вероятностная модель последовательности, которая: |
| - | + | # состоит из набора наблюдаемых переменных <math> X = {x_1 , \dots , x_N }, n_n \in R_d</math> и латентных (скрытых) переменных <math>T = {t_1, \dots, t_N },\;t_n \in \{0, 1\}^K,\;\sum_{j = 1}^{K}t_{nj}=1</math>. | |
| - | + | # латентные переменные T являются бинарными и кодируют K состояний, поэтому их иногда называют переменными состояния. | |
| - | ''Скрытая Марковская модель'' (первого порядка) — это вероятностная модель последовательности, которая | + | # значение наблюдаемого вектора <math>x_n</math> , взятого в момент времени <math>n</math>, зависит только от скрытого состояния <math>t_n</math>, которое в свою очередь зависит только от скрытого состояния в предыдущий момент времени <math>t_{n-1}</math>. |
| - | + | # для полного задания модели достаточно задать все условные распределения вида <math>p(x_n |t_n ),\;p(t_n |t_{n-1})</math> и априорное распределение <math>p(t_1)</math>. | |
| - | + | ||
| - | + | ||
| - | + | ||
Пусть имеется <math>K</math> возможных состояний. Закодируем состояние в каждый момент времени <math>n</math> бинарным вектором <math>t_n = (t_{n1},\dots, t_{nK})</math>, где <math>t_{nj} = 1</math>, если в момент <math>n</math> модель находится в состоянии <math>j</math> и <math>t_{nj} = 0</math>, иначе. | Пусть имеется <math>K</math> возможных состояний. Закодируем состояние в каждый момент времени <math>n</math> бинарным вектором <math>t_n = (t_{n1},\dots, t_{nK})</math>, где <math>t_{nj} = 1</math>, если в момент <math>n</math> модель находится в состоянии <math>j</math> и <math>t_{nj} = 0</math>, иначе. | ||
| Строка 160: | Строка 159: | ||
p(t_n |t_{n-1}) = \prod_{i=1}^K\prod_{j=1}^K A_{ij}^{t_{n-1,i}t_{nj}} | p(t_n |t_{n-1}) = \prod_{i=1}^K\prod_{j=1}^K A_{ij}^{t_{n-1,i}t_{nj}} | ||
</math> | </math> | ||
| - | Пусть в первый момент времени <math>p(t_{1j} = 1) = \pi_j</math>. Тогда | + | Пусть в первый момент времени <math>p(t_{1j} = 1) = \pi_j</math>. Тогда <math> p(t_1) = \prod_{j=1}^K \pi_j^{t_{1j}}</math> |
| - | <math> | + | |
| - | p(t_1) = \prod_{j=1}^K \pi_j^{t_{1j}} | + | |
| - | </math> | + | |
* Хотя матрица A может быть произвольного вида с учетом ограничений на неотрицательность и сумму элементов строки, с точки зрения СММ представляет интерес диагональное преобладание матрицы перехода. | * Хотя матрица A может быть произвольного вида с учетом ограничений на неотрицательность и сумму элементов строки, с точки зрения СММ представляет интерес диагональное преобладание матрицы перехода. | ||
| Строка 171: | Строка 167: | ||
* Условное распределение <math>p(x_n |t_n)</math> определяется текущим состоянием <math>t_n</math> | * Условное распределение <math>p(x_n |t_n)</math> определяется текущим состоянием <math>t_n</math> | ||
* Обычно предполагают, что оно нам известно с точностью до параметров <math>\phi_k,\;k \in \{1,\dots, K\}</math>, т.е. если <math>t_{n1} = 1</math>, то <math>x_n</math> взят из распределения <math>p(x_n |\phi_1 )</math>, если <math>t_{n2} = 1</math>, то <math>x_n</math> взят из распределения <math>p(x_n |\phi_2 )</math>, и т.д. | * Обычно предполагают, что оно нам известно с точностью до параметров <math>\phi_k,\;k \in \{1,\dots, K\}</math>, т.е. если <math>t_{n1} = 1</math>, то <math>x_n</math> взят из распределения <math>p(x_n |\phi_1 )</math>, если <math>t_{n2} = 1</math>, то <math>x_n</math> взят из распределения <math>p(x_n |\phi_2 )</math>, и т.д. | ||
| - | * Таким образом | + | * Таким образом <math> p(x_n |t_n) = \prod_{j=1}^K(p(x_n |\phi_k ))^{t_{nk}} </math> |
| - | <math> | + | |
| - | p(x_n |t_n) = \prod_{j=1}^K(p(x_n |\phi_k ))^{t_{nk}} | + | |
| - | </math> | + | |
Обозначим полный набор параметров <math>\Theta = \{\pi, A, \phi\}</math>. | Обозначим полный набор параметров <math>\Theta = \{\pi, A, \phi\}</math>. | ||
| - | ''' | + | '''Обучение с учителем'''. Известна некоторая последовательность <math>X</math>, для которой заданы <math>T</math>. '''Задача состоит''' в оценке по обучающей выборке набора параметров <math>\Theta</math>. |
| + | |||
| + | ==Алгоритм динамического программирования и его применение в скрытых марковских моделях.== | ||
| + | * см. '''Лекция 3, стр. 9-28''' | ||
| + | <br/> | ||
| + | '''Динамическое программирование''' в математике и теории вычислительных систем — метод решения задач с оптимальной подструктурой и перекрывающимися подзадачами, который намного эффективнее, чем решение «в лоб». ([http://ru.wikipedia.org/wiki/%D0%94%D0%B8%D0%BD%D0%B0%D0%BC%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5 дин. прогр. на вики]) | ||
| + | |||
| + | |||
| + | '''Собственно, билет'''. | ||
* Пусть известна некоторая последовательность наблюдений <math>X</math> и набор параметров СММ <math>\Theta</math>. Требуется определить наиболее вероятную последовательность состояний <math>T</math>, т.е. найти <math>arg\;max_T p(T|X, \Theta)</math>. | * Пусть известна некоторая последовательность наблюдений <math>X</math> и набор параметров СММ <math>\Theta</math>. Требуется определить наиболее вероятную последовательность состояний <math>T</math>, т.е. найти <math>arg\;max_T p(T|X, \Theta)</math>. | ||
* Заметим, что <math>p(X|\Theta)</math> не зависит от <math>T</math>, поэтому <math>arg\;max_T p(T|X, \Theta) = arg\;max_T \frac{p(X, T|\Theta)}{p(X|\Theta)} = arg\;max_T p(X, T|\Theta) = arg\;max_T log\,p(X, T|\Theta)</math>. | * Заметим, что <math>p(X|\Theta)</math> не зависит от <math>T</math>, поэтому <math>arg\;max_T p(T|X, \Theta) = arg\;max_T \frac{p(X, T|\Theta)}{p(X|\Theta)} = arg\;max_T p(X, T|\Theta) = arg\;max_T log\,p(X, T|\Theta)</math>. | ||
* Но это же классическая задача динамического программирования! | * Но это же классическая задача динамического программирования! | ||
<br> | <br> | ||
| - | ''Алгоритм Витерби'' | + | ''Алгоритм Витерби'' ([http://ru.wikipedia.org/wiki/%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_%D0%92%D0%B8%D1%82%D0%B5%D1%80%D0%B1%D0%B8 Алгоритм Витерби на вики] - очень хорошо для понимания зачем все это надо) |
| + | |||
Логарифм совместной плотности по распределению: | Логарифм совместной плотности по распределению: | ||
<math> | <math> | ||
| Строка 199: | Строка 201: | ||
== ЕМ-алгоритм и его применение в скрытых марковских моделях.== | == ЕМ-алгоритм и его применение в скрытых марковских моделях.== | ||
| + | |||
| + | === Максимум неполного правдоподобия === | ||
| + | |||
| + | * Предположим имеется графическая модель в которой известная только часть значений переменных. | ||
| + | * Атомарные распределения известны с точностью до <math>\theta</math> | ||
| + | * Требуется оценить параметры по наблюдаемым величинам с помощью метода максимального правдоподобия т.е найти <math> \theta_{ML} = \arg \max(p(X|\theta)) </math> | ||
| + | * По правилу суммирования вероятностей неполное правдоподобие может быть получено в виде суммирования по скрытым переменным полного правдоподобия <math>p(X|\theta)=\sum_T p(X,T|\theta)</math> | ||
| + | * Во многих случаях(в частности в байесовских сетях) подсчет полного правдоподобия тривиален | ||
| + | * При оптимизации правдоподобия удобно переходить к логарифму, в частности ранее в курсе мы получили явные формулы для <math>\arg \max_\theta(p(X|\theta)=\arg \max_\theta log(p(X|\theta)</math> в СММ | ||
| + | * Прямая оптимизация логарифма неполного правдоподобия очень затруднительн, даже в итерационной форме, т.к. фунционал имеет вид "логарифма суммы",в то время как удобно оптимизировать "сумму логарифов". | ||
| + | |||
| + | === Схема ЕМ-алгоритма === | ||
| + | * на входе: выборка X, зависящая от набора параметров <math>\theta</math> | ||
| + | * Инициализируем <math>\theta</math> некоторыми начальным приближением | ||
| + | * Е-шаг: оцениваем распределение скрытой компоненты | ||
| + | <math> p(T|X,\theta_{old})=\frac{p(X|T,\theta_{old})}{\sum_T p(X,T|\theta_{old})} </math> | ||
| + | * M-шаг оптимизируем | ||
| + | <math>\mathbb E_{T|X,\theta_{old}} log(p(X,T|\theta))=\sum_T p(X|T,\theta_{old})log( p(X,t|\theta)) \to \max_{\theta} </math> <br> | ||
| + | Если бы мы точно знали значение <math>T=T_0</math>, то вместо мат. ожидания по всевозможным(с учетом наблюдаемых данных) <math> T|X,\theta_{old} </math> мы бы оптимизировали <math> log(p(X,T_0|\theta)) </math> | ||
| + | *Переход к E-шагу пока процесс не сойдется | ||
| + | *Оптимизация проводится итерационно методом покоординатного спуска: на каждой итерации последовательно уточняются возможные значения Т (Е-шаг), а потом пересчитываются значения <math>\theta</math> (М-шаг) | ||
| + | *Во многих случаях на М-шаге можно получить явные формулы, т.к. там происходит оптимизация выпуклой комбинации логарифмов полных правдоподобий, имеющей вид взвешенной "суммы лоагрифмов" | ||
| + | |||
| + | |||
| + | === EM-алгоритм для смеси гауссовских распределений === | ||
| + | см. пункт 1.6 | ||
| + | недостатки: | ||
| + | * В зависимости от выбора начального приближения может сходится к разным точкам | ||
| + | * ЕМ-алгоритм находит локальный экстремум, в котором значение правдоподобия может оказаться намного ниже, чем в глобальном варианте | ||
| + | * ЕМ-алгоритм не позволяет определить количество компонентов смеси l | ||
| + | * !!Величина l является структурным параметром(в начале лекций говорилось о них) | ||
| + | |||
== Условная независимость в скрытых марковских моделях. Алгоритм «вперед-назад».== | == Условная независимость в скрытых марковских моделях. Алгоритм «вперед-назад».== | ||
| + | * ''Лекция 4, Слайды 16-28'' | ||
| + | * [http://ru.wikipedia.org/wiki/%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_%D0%B2%D0%BF%D0%B5%D1%80%D1%91%D0%B4-%D0%BD%D0%B0%D0%B7%D0%B0%D0%B4 вики] | ||
| + | |||
| + | '''Алгоритм «вперёд-назад»''' -- алгоритм для вычисления апостериорных вероятностей последовательности состояний при наличии последовательности наблюдений. Или по другому, алгоритм для того, чтобы вычислить вероятность специфической последовательности наблюдений. Это работает в контексте скрытых Марковских моделей. | ||
| + | * работает за линейное по количеству наблюдаемых переменных (<math>N</math>) | ||
| + | |||
| + | Алгоритм включает три шага: | ||
| + | # вычисление прямых вероятностей | ||
| + | # вычисление обратных вероятностей | ||
| + | # вычисление сглаженных значений | ||
| + | |||
==Метод релевантных векторов в задаче восстановления регрессии.== | ==Метод релевантных векторов в задаче восстановления регрессии.== | ||
| + | Лекция 5 Ветров. | ||
| + | |||
== Метод релевантных векторов в задаче классификации.== | == Метод релевантных векторов в задаче классификации.== | ||
| + | Лекция 5 Ветров. | ||
| + | |||
| + | [http://courses.graphicon.ru/files/courses/smisa/2008/lectures/lecture11.pdf Еще слайды Ветрова, но не из этого круса] от того более понятными не становятся | ||
| + | |||
== Метод главных компонент.== | == Метод главных компонент.== | ||
| Строка 209: | Строка 260: | ||
* проекция данных на гиперплоскость с наименьшей ошибкой проектирования | * проекция данных на гиперплоскость с наименьшей ошибкой проектирования | ||
* поиск проекции на гиперплоскость с сохранением большей части дисперсии в данных | * поиск проекции на гиперплоскость с сохранением большей части дисперсии в данных | ||
| + | |||
| + | [http://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D0%BE%D0%B4_%D0%B3%D0%BB%D0%B0%D0%B2%D0%BD%D1%8B%D1%85_%D0%BA%D0%BE%D0%BC%D0%BF%D0%BE%D0%BD%D0%B5%D0%BD%D1%82 Википедия: Метод главных компонент] | ||
==Вероятностная формулировка метода главных компонент.== | ==Вероятностная формулировка метода главных компонент.== | ||
| Строка 230: | Строка 283: | ||
== Метод главных компонент. Схема автоматического выбора числа главных компонент.== | == Метод главных компонент. Схема автоматического выбора числа главных компонент.== | ||
== Недостатки метода главных компонент. Метод независимых компонент.== | == Недостатки метода главных компонент. Метод независимых компонент.== | ||
| + | '' Лекция 6, слайды 42-46 '' | ||
| + | |||
<u>Недостатки метода главных компонент:</u> | <u>Недостатки метода главных компонент:</u> | ||
* возможны только линейные подпространства, объясняющие данные с высокой точностью. на практике часто такие поверхности могут быть сложными криволинейными. | * возможны только линейные подпространства, объясняющие данные с высокой точностью. на практике часто такие поверхности могут быть сложными криволинейными. | ||
| Строка 244: | Строка 299: | ||
== Нелинейные методы уменьшения размерности. Локальное линейное погружение.== | == Нелинейные методы уменьшения размерности. Локальное линейное погружение.== | ||
| + | '' Лекция 6, слайды 48-50 '' | ||
| + | |||
| + | PCA не позволяет находить преобразования, которые основаны на том факте, что близкие объекты на некоторой поверхности, были бы близки и в новом пространстве. то есть все наши наблюдения сосредотачиваются на некоторой (совсем не факт, что линейной) поверхности. Задача - восстановить эту поврехность | ||
| + | |||
| + | LLE ( локальное линейное погружение ) -- метод, основанный на поиске преобразования с учётом сохранения отношения соседства между объектами | ||
| + | |||
== Нелинейные методы уменьшения размерности. Ассоциативные нейронные сети и GTM.== | == Нелинейные методы уменьшения размерности. Ассоциативные нейронные сети и GTM.== | ||
| + | '' Лекция 6, слайды 51-55 '' | ||
= Часть 2 (Рудаков) = | = Часть 2 (Рудаков) = | ||
| Строка 288: | Строка 350: | ||
Теперь поговорим об '''информативности''' (или качестве) признака. | Теперь поговорим об '''информативности''' (или качестве) признака. | ||
| - | Своими словами: предикат \varphi тем более информативен, чем больше он выделяет объектов "своего класса" <math>c \in Y</math> по сравнению с объектами всех остальных "чужих" классов. Свои объекты называют также <u>''позитивными''</u> (positive), а чужие <u>''негативными''</u> (negative). Введём следующие обозначения: | + | Своими словами: предикат <math>\varphi</math> тем более информативен, чем больше он выделяет объектов "своего класса" <math>c \in Y</math> по сравнению с объектами всех остальных "чужих" классов. Свои объекты называют также <u>''позитивными''</u> (positive), а чужие <u>''негативными''</u> (negative). Введём следующие обозначения: |
* <math>P_c</math> - число объектов класса c в выборке X | * <math>P_c</math> - число объектов класса c в выборке X | ||
* <math>p_c(\varphi)</math> - из них число объектов, для которых выполняется условие <math>\varphi(x) = 1</math>; | * <math>p_c(\varphi)</math> - из них число объектов, для которых выполняется условие <math>\varphi(x) = 1</math>; | ||
| Строка 303: | Строка 365: | ||
Для начала, поговорим об '''алгоритмах голосования'''. Пусть для каждого класса <math>c \in Y</math> построено множество логических закономерностей (правил), специализирующихся на различении объектов данного класса: | Для начала, поговорим об '''алгоритмах голосования'''. Пусть для каждого класса <math>c \in Y</math> построено множество логических закономерностей (правил), специализирующихся на различении объектов данного класса: | ||
| - | <math>R_c = { \varphi_c^t : X \rightarrow {0, 1} | t = 1, . . . , T_c}</math>, где <math>T_c</math> - количество классов свойств. | + | <math>R_c = \{ \varphi_c^t : X \rightarrow \{0, 1\} | t = 1, . . . , T_c\}</math>, где <math>T_c</math> - количество классов свойств. |
Считается, что если <math>\varphi_c^t (x) = 1</math>, то правило <math>\varphi_c^t</math> относит объект <math>x \in X</math> к классу c. Если же <math>\varphi_c^t(x) = 0 </math>, то правило <math>\varphi_c^t</math> воздерживается от классификации объекта x. | Считается, что если <math>\varphi_c^t (x) = 1</math>, то правило <math>\varphi_c^t</math> относит объект <math>x \in X</math> к классу c. Если же <math>\varphi_c^t(x) = 0 </math>, то правило <math>\varphi_c^t</math> воздерживается от классификации объекта x. | ||
| Строка 339: | Строка 401: | ||
** Короткие конъюнкции легко интерпретируются в терминах предметной области. Алгоритм способен не только классифицировать объекты, но и объяснять свои решения на языке, понятном специалистам. | ** Короткие конъюнкции легко интерпретируются в терминах предметной области. Алгоритм способен не только классифицировать объекты, но и объяснять свои решения на языке, понятном специалистам. | ||
** При малых K (не больше 3) алгоритм очень эффективен | ** При малых K (не больше 3) алгоритм очень эффективен | ||
| - | ** Если короткие информативные конъюнкции существуют, они обязательно | + | ** Если короткие информативные конъюнкции существуют, они обязательно будут найдены, так как алгоритм осуществляет полный перебор. |
| - | + | ||
* <u>Недостатки алгоритма</u> | * <u>Недостатки алгоритма</u> | ||
** При неудачном выборе множества предикатов <math>B</math> коротких информативных конъюнкций может просто не существовать. В то же время, увеличение числа K приводит к экспоненциальному падению эффективности. | ** При неудачном выборе множества предикатов <math>B</math> коротких информативных конъюнкций может просто не существовать. В то же время, увеличение числа K приводит к экспоненциальному падению эффективности. | ||
| Строка 395: | Строка 456: | ||
* совокупность из всех подмножеств из k элементов. его мощность: <math>C^n_k</math> | * совокупность из всех подмножеств из k элементов. его мощность: <math>C^n_k</math> | ||
| - | ''' Функция близости ''' <math>\mathcal{N} | + | ''' Функция близости ''' <math>\mathcal{N}_{\tilde\Omega}(S_i, S_j)</math> -- задает расстояние между проекциями объектов <math>S_i</math> и <math>S_j</math> на <math>\tilde\Omega \in \Omega</math>. В дальнейшем рассматриваются только такие функции <math>\mathcal{N}_{\tilde \Omega}</math>, которые принимают значения 0 или 1 (бинарные). |
<u>Три вида функции близости:</u> | <u>Три вида функции близости:</u> | ||
| - | # | + | # Введем неотрицательные параметры <math>\varepsilon_i > 0 ~,~ i \in [1,n]</math>. Пусть <math>\tilde\Omega=\{u_1, \dots, u_k\}</math>. Тогда <math>\mathcal{N}_{\tilde\Omega}(S_i, S_j) = |
\begin{cases} | \begin{cases} | ||
| - | 1,~~\rho(\alpha_{ | + | 1,~~\rho(\alpha_{i,u_l}, \alpha_{j,u_l}) \leqslant \varepsilon_{u_l}~~\forall l \in [1,k]\\ |
| - | 0,~~ | + | 0,~~otherwise |
\end{cases}</math> | \end{cases}</math> | ||
| - | # | + | # Введем дополнительно к п.1 параметр <math>\nu</math> такой, что функция близости будет определятся как <math>\mathcal{N}_{\tilde\Omega}(S_i, S_j) = 1</math>, если не выполнено не больше, чем <math>\nu</math> описанных неравенств. при этом имеет смысл брать <math>0 \leqslant \nu \leqslant \left[\frac{k}{2} - 1\right] </math> |
| - | # | + | # Вместо <math>\nu</math> определяем <math>\nu'</math> и функцию близости так, что <math>\mathcal{N}_{\tilde\Omega}(S_i,S_j) = 1</math>, если из k неравенств не выполнены r, причем <math>\frac{r}{k} < \nu'</math> |
| + | * К билету был вопрос: какие сколько возможных выборок<math>\varepsilon_i</math> стоит рассматривать. Вообще говоря <math>\varepsilon</math> -действительно так-что континуум. Но смысл будут нести только l*m*n вариантов. где l - число признаков(колчисетво этих <math>\varepsilon</math> ),m - число компонент обучающей выборки, n - число компонент контрольной выборки. Другими словами мы <math>\varepsilon_i</math> задаем какое хотим, но обычно его задают между значениями признаков на выборке, при этом всего у нас m*n сравнений и таким образом m*n вариантов его задать(для одного <math>\varepsilon</math> ) | ||
== Формулы вычисления оценок. Эвристические обоснования. == | == Формулы вычисления оценок. Эвристические обоснования. == | ||
| Строка 410: | Строка 472: | ||
''' Формула вычисления оценок: ''' | ''' Формула вычисления оценок: ''' | ||
| - | <math>\Gamma_1^j ( | + | <math>\Gamma_1^j (S) = \sum_{\tilde \Omega \in \Omega} \sum_{k : P_j(S_k) = 1} \gamma_k \cdot P_{\tilde \Omega} \cdot \mathcal{N}_{\tilde \Omega}(S, S_k)</math>, где: |
| - | * <math> | + | * <math>\tilde \Omega \in \Omega</math> -- опорные множества |
| - | * <math> | + | * <math>P_j(S_k) = 1</math> если объект <math>S_k</math> входит в класс <math>j</math>. |
| - | * <math>\gamma_k</math> -- вес объекта | + | * <math>\gamma_k</math> -- вес объекта <math>S_k</math>. |
| - | * <math> | + | * <math>P_{\tilde \Omega}</math> -- вес опорного множества. |
| - | <math>\Gamma_0^j ( | + | <math>\Gamma_0^j (S) = \sum_{\tilde \Omega \in \Omega} \sum_{k : P_j(S_k) = 0} \gamma_k \cdot P_{\tilde \Omega} \cdot \mathcal{N}_{\tilde \Omega}(S, S_k)</math>, где: |
| - | * <math> | + | * <math>P_j(S_k) = 0</math> если объект <math>S_k</math> не входит в класс <math>j</math>. |
| - | <math>\Gamma^j( | + | Итоговая формула для оценки принадлежности объекта <math>S</math> классу <math>j</math>: |
| + | |||
| + | <math>\Gamma^j(S) = x_1 \cdot \Gamma_1^j (S) + x_2 \cdot \Gamma_0^j (S)</math>, где <math>x_1, x_2</math> -- коэффициенты, которые определяют работу с соответствующими характеристиками. | ||
== Задачи оптимизации АВО. Совместные подсистемы систем неравенств. == | == Задачи оптимизации АВО. Совместные подсистемы систем неравенств. == | ||
| - | + | * [http://www.cmcspec.ru/ipb/index.php?showtopic=536&view=findpost&p=15844 lekcii_ama_zuravlev.doc], пункт 2.4 | |
| - | [http://www.mipt.ru/nauka/51conf/dokl/In_prac_fupm/m_3rhk32/m_3rhknp.html | + | * [http://www.mipt.ru/nauka/51conf/dokl/In_prac_fupm/m_3rhk32/m_3rhknp.html Оптимизация АВО по метрикам] |
== Функционалы качества. Сложность моделей алгоритмов и проблема переобучения. == | == Функционалы качества. Сложность моделей алгоритмов и проблема переобучения. == | ||
'''Функционал качества''' алгоритма. | '''Функционал качества''' алгоритма. | ||
| - | Пусть задана таблица контрольных объектов (множество объектов, на которых мы будет проверять качество работы нашего алгоритма распознавания). Для контрольных объектов мы должны знать, | + | Пусть задана таблица контрольных объектов (множество объектов, на которых мы будет проверять качество работы нашего алгоритма распознавания). Для контрольных объектов мы должны знать, к какому классу свойств относится каждый из объектов (иначе как мы будет проверять корректность работы нашего алгоритма). Подаем контрольные объекты на вход алгоритму. Доля правильных ответов, выданных алгоритмов - это и есть ''функционал качества'' (в простейшем случае). |
| Строка 439: | Строка 503: | ||
== Общие пространства начальных и финальных информаций. Задачи синтеза корректных алгоритмов. == | == Общие пространства начальных и финальных информаций. Задачи синтеза корректных алгоритмов. == | ||
| + | [http://www.ccas.ru/frc/thesis/RudakovDocDisser.pdf Диссертация Рудакова], пункт 1.1 | ||
| + | |||
В самой общей постановке задача синтеза алгоритмов преобразования информаций состоит в следующем. Имеется множество начальных информаций <math>\Im_i</math> и множество конечных информаций <math>\Im_j</math>. Требуется построить алгоритм реализующий отображение из <math>\Im_i</math> в <math>\Im_j</math>, удовлетворяющее заданной системе ограничений. | В самой общей постановке задача синтеза алгоритмов преобразования информаций состоит в следующем. Имеется множество начальных информаций <math>\Im_i</math> и множество конечных информаций <math>\Im_j</math>. Требуется построить алгоритм реализующий отображение из <math>\Im_i</math> в <math>\Im_j</math>, удовлетворяющее заданной системе ограничений. | ||
| Строка 450: | Строка 516: | ||
[http://www.ccas.ru/frc/thesis/RudakovDocDisser.pdf Диссертация Рудакова], пункт 1.5 | [http://www.ccas.ru/frc/thesis/RudakovDocDisser.pdf Диссертация Рудакова], пункт 1.5 | ||
| + | |||
| + | '''Разрешимые''' задачи - это задачи, для которых множество допустимых отображений их <math>\mathfrak{I}_i</math> в <math>\mathfrak{I}_f</math> непусто, т.е. существуют семейства алгоритмов, содержащие их решения. | ||
| + | Задача Z из множества задач <math>\mathfrak{Z} </math> называется ''полной'' относительно семейства <math>\mathfrak{M} </math> отображений из <math>\mathfrak{I}_i</math> в <math>\mathfrak{I}_f</math>, если в <math>\mathfrak{M} </math> содержатся допустимые отображения для всех задач из класса эквивалентности, содержащего Z. | ||
| + | Задача Z называется '''регулярной''', если для нее существует семейство отображений <math>\mathfrak{M} </math>, относительно которого она полна. | ||
| + | |||
| + | '''Регулярность по Журавлеву''': | ||
| + | Пусть есть <math>q</math> объектов и <math>l</math> классов и | ||
| + | <math>\hat{I}=||I_{ij}||_{q \times l}</math> - матрица информации и <math> \hat {\tilde I} = || {\tilde I}_{ij}||_{q \times l}</math> - матрица правильных ответов. | ||
| + | Задаче Z соответствует пара матриц: <math> Z \leftrightarrow (\hat I , \hat{\tilde I})</math>. | ||
| + | Определение ''окрестности задачи по Журавлеву'' <math>O(Z)=\{Z^' |Z^' \leftrightarrow (\hat I , \hat{\tilde I}^')\}</math> - т.е. это множество задач <math>Z^'</math>, получающихся всевозможным варьированием матрицы правильных ответов. | ||
| + | |||
| + | * Разбиваем множество задач на классы эквивалентности. Задача называется регулярной если она разрешима и разрешимы все задачи из класса эквивалентности который она порождает. | ||
== Операции над алгоритмами. Расширение моделей. == | == Операции над алгоритмами. Расширение моделей. == | ||
| Строка 464: | Строка 542: | ||
Диссертация Рудакова 1.3 + 1.5 пункты. | Диссертация Рудакова 1.3 + 1.5 пункты. | ||
Диссертация Рудакова, пункт 3.5 | Диссертация Рудакова, пункт 3.5 | ||
| + | |||
| + | |||
| + | Модель алгоритмов <math>\mathfrak{M}</math> категории <math>\Phi_0</math> называется полной, если любая регулярная задача <math>Z</math> из множества <math>\mathfrak{Z}_{[R]}</math> полна относительно <math>\mathfrak{M}</math>, т.е. если для любой регулярной задачи <math>Z</math> модель алгоритмов от любой матрицы исходных информаций этой задачи приводит в множество конечных информаций. | ||
| + | (т.е. в модели алгоритмов <math>\mathfrak{M}</math> для каждой регулярной задачи из множества <math>\mathfrak{Z}_{[R]}</math> содержится корректный алгоритм) | ||
== Дополнительные к прецедентам ограничения. Пример: перестановочность строк и столбцов в матрицах информации. == | == Дополнительные к прецедентам ограничения. Пример: перестановочность строк и столбцов в матрицах информации. == | ||
| Строка 473: | Строка 555: | ||
Пусть рассматривается задача, в которой имеется информация о том, что порядок, в котором анализируются классы несущественен, и кроме прецедентных данных нет сведений о различии классов. | Пусть рассматривается задача, в которой имеется информация о том, что порядок, в котором анализируются классы несущественен, и кроме прецедентных данных нет сведений о различии классов. | ||
Универсальные ограничения, выражающие однородность классов, состоят в том, что отображение, реализуемое корректным алгоритмом, должно коммутировать со всеми подстановками столбцов (при любой перстановке столбцов в матрице информации точно так же должны переставляться столбцы в матрице, порожденной алгоритмом). | Универсальные ограничения, выражающие однородность классов, состоят в том, что отображение, реализуемое корректным алгоритмом, должно коммутировать со всеми подстановками столбцов (при любой перстановке столбцов в матрице информации точно так же должны переставляться столбцы в матрице, порожденной алгоритмом). | ||
| - | |||
| - | === '''Задачи с однородными объектами''' === | ||
| - | |||
| - | Пусть рассматривается задача, в которой имеется информация о том, что порядок, в котором анализируются объекты несущественен, и кроме прецедентных данных нет сведений о различии объектов. | ||
| - | Универсальные ограничения, выражающие однородность объектов, состоят в том, что отображение, реализуемое корректным алгоритмом, должно коммутировать со всеми подстановками строк (при любой перстановке строк в матрице информации точно так же должны переставляться строки в матрице, порожденной алгоритмом). | ||
== Задачи с непересекающимися классами. == | == Задачи с непересекающимися классами. == | ||
| + | Диссертация Рудакова, пункт 2.5 | ||
== Класс поэлементных операций и отображений. Условия регулярности и полноты. == | == Класс поэлементных операций и отображений. Условия регулярности и полноты. == | ||
== Полнота моделей АВО. == | == Полнота моделей АВО. == | ||
| + | Диссертация Рудакова, пункт 3.5 | ||
== Полнота полиномиальных семейств корректирующих операций. == | == Полнота полиномиальных семейств корректирующих операций. == | ||
| Строка 493: | Строка 572: | ||
Для частного случая - матрицы информации, состоящие из нулей и единиц, оценку степени корректирующих полиномов удалось улучшить. Для таких полиномов степень может быть снижена до <math>\lceil \log_2 (q * l ) \rceil</math> | Для частного случая - матрицы информации, состоящие из нулей и единиц, оценку степени корректирующих полиномов удалось улучшить. Для таких полиномов степень может быть снижена до <math>\lceil \log_2 (q * l ) \rceil</math> | ||
| + | |||
| + | |||
| + | Полезная информация к билету из [http://www.ccas.ru/frc/thesis/RudakovDocDisser.pdf Диссертации Рудакова] | ||
| + | * Определение корректирующих операций - п. 1.3 стр 27 | ||
| + | * Полнота полиномиальных семейств к.о. - п. 5.6 стр 116 | ||
| + | * Определение 0,1-полноты - определение 6.1.2 стр 119 | ||
| + | * Теорема о логарифмической границе степени корректирующих полиномов - теорема 6.1.3, стр 120 | ||
| + | |||
| + | |||
| + | {{Курс МОТП}} | ||
Текущая версия
[править] Часть 1 (Ветров)
[править] Метод максимального правдоподобия. Его достоинства и недостатки
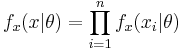 для независимой выборки n величин.
для независимой выборки n величин.Недостатки:
- нужно знать априорное распределение (с точностью до параметров) наблюдаемой величины
- хорошо применим при допущении, что
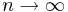 (асимптотически оптимален), что в реальности не так
(асимптотически оптимален), что в реальности не так
- проблема выбора структурных параметров, позволяющих избегать переобучения (проблема вообще всех методов машинного обучения)
- необходима регуляризация метода
[править] Решение несовместных СЛАУ
В статистике, машинном обучении и теории обратных задач под регуляризацией понимают добавление некоторой дополнительной информации к условию с целью решить некорректно поставленную задачу или предотвратить переобучение.
- всегда единственно
- при небольших λ определяет псевдорешение с наименьшей нормой
- любое псевдорешение имеет минимальную невязку
[править] Задача восстановления линейной регрессии. Метод наименьших квадратов
Задача регрессионного анализа (неформально): предположим, имеется зависимость между неизвестной нам случайно величиной X (мы судим о ней по наблюдаемым признакам, т.е. по случайной выборке) и некоторой переменной (параметром) t.
Искомая зависимость среднего значения X от значений Z обозначается через функцию f(t): E(X | Z = t) = f(t). Проводя серии экспериментов, требуется по значениям t1, …, tn и X1, …, Xn оценить как можно точнее функцию f(t).
Однако, наиболее простой и изученной является линейная регрессия, в которой неизвестные настраиваемые параметры (wj) входят в решающее правило линейно с коэффициентами ψj(x): 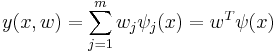 /
/
Пример (простой пример на пальцах): Linear Regression Example.
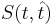 — функция потерь от ошибки. На пальцах: берем найденную путем регрессии функцию
— функция потерь от ошибки. На пальцах: берем найденную путем регрессии функцию 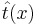 и сравниваем её выдачу на тех же наборах x, что и заданные результаты эксперимента t(x).
и сравниваем её выдачу на тех же наборах x, что и заданные результаты эксперимента t(x).
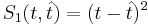
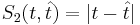
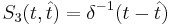
Основная задача — минимизировать эту функцию, что значит минимизировать 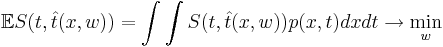 .
.
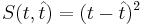 .
.Особенности квадратичной функции потерь:
- Достоинтсва:
- Гладкая (непрерывная и дифференцируемая);
- Решение может быть получено в явном виде.
- Недостатки:
- Решение неустойчиво;
- Не применима к задачам классификации.
[править] Задача восстановления линейной регрессии. Вероятностная постановка
Представим регрессионную переменную как случайную величину с плотностью распределения p(t | x).
В большинстве случаев предполагается нормальное распределение относительно некоторой точки y(x): 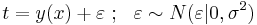 .
.
Максимизируя правдоподобие (оно задается следующей формулой: 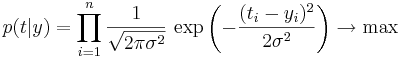 ), получаем эквивалентность данного метода методу наименьших квадратов, т. к. взяв логарифм от формулы выше, получаем:
), получаем эквивалентность данного метода методу наименьших квадратов, т. к. взяв логарифм от формулы выше, получаем:
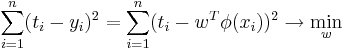
[править] Логистическая регрессия. Вероятностная постановка
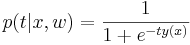 (сигмоид).
(сигмоид).Эта функция является функцией правдоподобия по w и распределением вероятности по t, т.к. 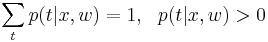 .
.
[править] ЕМ-алгоритм для задачи разделения гауссовской смеси
Пусть имеется выборка 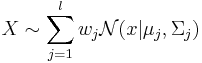 , где l - число компонент смеси.
, где l - число компонент смеси.
EM-алгоритм: (en-wiki], machinelearning-пример)
- Выбираем начальное приближение для параметров
![\mu_j, \Sigma_j, w_j, j \isin [1, l]](/w/images/math/8/7/5/875ccc07511185c8273735c7665905bc.png) .
.
- E-шаг (expectation): находим для каждого элемента выборки вероятность, с которой он принадлежит каждой из компонент смеси.
- M-шаг (maximization): с учетом вероятностей на предыдущем шаге пересчитываем коэффициенты начального шага.
- Переход к E шагу до тех пор, пока не будет достигнута сходимость.
Недостатки:
- (!) Не позволяет определить количество компонент смеси (l).
- Величина l является структурным параметром.
- В зависимости от выбора начального приближения может сходиться к разным точкам.
- может сваливаться в локальный экстремум.
[править] Основные правила работы с вероятностями. Условная независимость случайных величин
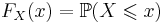 .
.- В дискретном случае — вероятность того, что X = x;
- В непрерывном случае — производная функции распределения.
Далее X, Y — случайные величины с плотностями вероятности p(x),p(y).
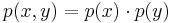 .
.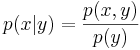 .
.
- в дискретном случае — вероятность того, что наступило событие x, при условие наступления события y.
Правило суммирования: пусть  — k взаимоисключающих события, одно из которых обязательно наступает. Тогда
— k взаимоисключающих события, одно из которых обязательно наступает. Тогда
-
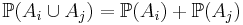
-
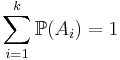
- Формула полной вероятности:
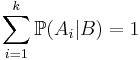 или
или 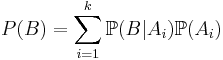 .
.
- В интегральном виде:
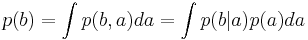 .
.
- Формула Байеса (ru:wiki):
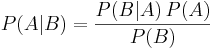 .
.
Случайные величины называются условно независимыми от z, если p(x,y | z) = p(x | z)p(y | z)
- Это значит: вся информация о взаимосвязи между x и y содержится в z.
- Из безусловной независимости не следует условная независимость.
- Основное свойство условно независимых величин:
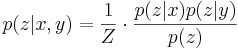 , где
, где 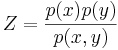 .
.
[править] Графические модели. Основные задачи, возникающие в анализе графических моделей
Графическая модель -- ориентированный или неориентированный граф, в котором вершины соответствуют переменным, а ребра - вероятностным отношениям, определяющим непосредственные зависимости.
Пусть X -- совокупность наблюдаемых переменных, T -- ненаблюдаемых.
Основные задачи:
- подсчёт условного распределния на значениях отдельной скрытой переменной: p(ti | X)
- нахождение наиболее вероятной конфигурации скрытых переменных при заданных наблюдаемых значениях:
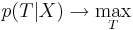
- оценка адекватности выбранной графической модели данным p(X)
[править] Байесовские сети. Примеры.
Байесовская сеть — это вероятностная модель, представляющая собой множество переменных и их вероятностных зависимостей.
(wiki: опред., принципы и пример) + см. презентации
Особенности:
- По смыслу построения байесовские сети не могут содержать ориентированные циклы, т.к. это будет нарушать правило умножения вероятностей
- Главным достоинством графических моделей является относительно простое выделение условно-независимых величин, которое облегчает дальнейший анализ, позволяя значительно уменьшить количество факторов, влияющих на данную переменную
[править] Марковские сети. Примеры.
[править] Скрытые марковские модели. Обучение СММ с учителем.
Скрытая Марковская модель (первого порядка) — это вероятностная модель последовательности, которая:
- состоит из набора наблюдаемых переменных
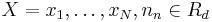 и латентных (скрытых) переменных
и латентных (скрытых) переменных 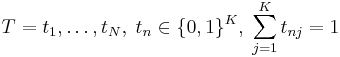 .
.
- латентные переменные T являются бинарными и кодируют K состояний, поэтому их иногда называют переменными состояния.
- значение наблюдаемого вектора xn , взятого в момент времени n, зависит только от скрытого состояния tn, которое в свою очередь зависит только от скрытого состояния в предыдущий момент времени tn − 1.
- для полного задания модели достаточно задать все условные распределения вида
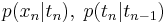 и априорное распределение p(t1).
и априорное распределение p(t1).
Пусть имеется K возможных состояний. Закодируем состояние в каждый момент времени n бинарным вектором 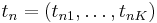 , где tnj = 1, если в момент n модель находится в состоянии j и tnj = 0, иначе.
, где tnj = 1, если в момент n модель находится в состоянии j и tnj = 0, иначе.
Тогда распределение p(tn | tn − 1) можно задать матрицей перехода A размера 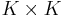 , где
, где
| Aij = p(tnj = 1 | tn − 1,i = 1), | ∑ | Aij = 1 |
| j |
, т.е. 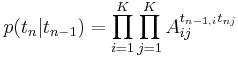 Пусть в первый момент времени p(t1j = 1) = πj. Тогда
Пусть в первый момент времени p(t1j = 1) = πj. Тогда 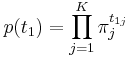
- Хотя матрица A может быть произвольного вида с учетом ограничений на неотрицательность и сумму элементов строки, с точки зрения СММ представляет интерес диагональное преобладание матрицы перехода.
- В этом случае можно ожидать, что процесс находится в некотором состоянии на протяжении какого-то отрезка времени.
- Появляется простая физическая интерпретация СММ: имеется процесс, который иногда (относительно редко) скачкообразно меняет свои характеристики.
- Условное распределение p(xn | tn) определяется текущим состоянием tn
- Обычно предполагают, что оно нам известно с точностью до параметров
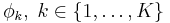 , т.е. если tn1 = 1, то xn взят из распределения p(xn | φ1), если tn2 = 1, то xn взят из распределения p(xn | φ2), и т.д.
, т.е. если tn1 = 1, то xn взят из распределения p(xn | φ1), если tn2 = 1, то xn взят из распределения p(xn | φ2), и т.д.
- Таким образом
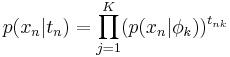
Обозначим полный набор параметров Θ = {π,A,φ}.
Обучение с учителем. Известна некоторая последовательность X, для которой заданы T. Задача состоит в оценке по обучающей выборке набора параметров Θ.
[править] Алгоритм динамического программирования и его применение в скрытых марковских моделях.
- см. Лекция 3, стр. 9-28
Динамическое программирование в математике и теории вычислительных систем — метод решения задач с оптимальной подструктурой и перекрывающимися подзадачами, который намного эффективнее, чем решение «в лоб». (дин. прогр. на вики)
Собственно, билет.
- Пусть известна некоторая последовательность наблюдений X и набор параметров СММ Θ. Требуется определить наиболее вероятную последовательность состояний T, т.е. найти
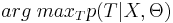 .
.
- Заметим, что p(X | Θ) не зависит от T, поэтому
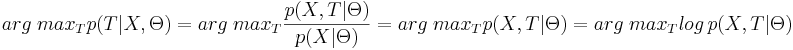 .
.
- Но это же классическая задача динамического программирования!
Алгоритм Витерби (Алгоритм Витерби на вики - очень хорошо для понимания зачем все это надо)
Логарифм совместной плотности по распределению:
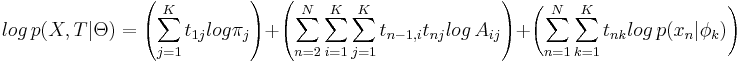
Функция Беллмана 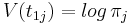
![V(t_{nj}) = max_i \left[ V(t_{n-1,i}) + \left(\sum_{i=1}^K\sum_{j=1}^K t_{n-1,i}t_{nj}log\,A_{ij}\right) + log\,p(x_n, \phi_j)\right]](/w/images/math/d/a/1/da1a575a4b4acdcc9fd65dbe58473509.png)
![S(t_{nj}) = arg\;max_i \left[ V(t_{n-1,i}) + \left(\sum_{i=1}^K\sum_{j=1}^K t_{n-1,i}t_{nj}log\,A_{ij}\right) + log\,p(x_n, \phi_j)\right]](/w/images/math/1/6/4/1647ce24db66b2a222d5cc7ee2b0e83a.png)
Выполнив прямой проход по сигналу, мы оцениваем V(tnj) и S(tnj), а выполнив обратный проход, мы получаем оптимальные номера оптимальных состояний 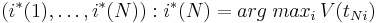
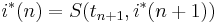
Легко видеть, что значения переменных tn определяются так: 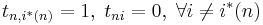
[править] ЕМ-алгоритм и его применение в скрытых марковских моделях.
[править] Максимум неполного правдоподобия
- Предположим имеется графическая модель в которой известная только часть значений переменных.
- Атомарные распределения известны с точностью до θ
- Требуется оценить параметры по наблюдаемым величинам с помощью метода максимального правдоподобия т.е найти θML = argmax(p(X | θ))
- По правилу суммирования вероятностей неполное правдоподобие может быть получено в виде суммирования по скрытым переменным полного правдоподобия
| p(X | θ) = | ∑ | p(X,T | θ) |
| T |
- Во многих случаях(в частности в байесовских сетях) подсчет полного правдоподобия тривиален
- При оптимизации правдоподобия удобно переходить к логарифму, в частности ранее в курсе мы получили явные формулы для argmaxθ(p(X | θ) = argmaxθlog(p(X | θ) в СММ
- Прямая оптимизация логарифма неполного правдоподобия очень затруднительн, даже в итерационной форме, т.к. фунционал имеет вид "логарифма суммы",в то время как удобно оптимизировать "сумму логарифов".
[править] Схема ЕМ-алгоритма
- на входе: выборка X, зависящая от набора параметров θ
- Инициализируем θ некоторыми начальным приближением
- Е-шаг: оцениваем распределение скрытой компоненты
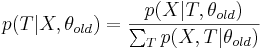
- M-шаг оптимизируем
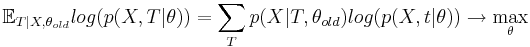
Если бы мы точно знали значение T = T0, то вместо мат. ожидания по всевозможным(с учетом наблюдаемых данных) T | X,θold мы бы оптимизировали log(p(X,T0 | θ))
- Переход к E-шагу пока процесс не сойдется
- Оптимизация проводится итерационно методом покоординатного спуска: на каждой итерации последовательно уточняются возможные значения Т (Е-шаг), а потом пересчитываются значения θ (М-шаг)
- Во многих случаях на М-шаге можно получить явные формулы, т.к. там происходит оптимизация выпуклой комбинации логарифмов полных правдоподобий, имеющей вид взвешенной "суммы лоагрифмов"
[править] EM-алгоритм для смеси гауссовских распределений
см. пункт 1.6 недостатки:
- В зависимости от выбора начального приближения может сходится к разным точкам
- ЕМ-алгоритм находит локальный экстремум, в котором значение правдоподобия может оказаться намного ниже, чем в глобальном варианте
- ЕМ-алгоритм не позволяет определить количество компонентов смеси l
- !!Величина l является структурным параметром(в начале лекций говорилось о них)
[править] Условная независимость в скрытых марковских моделях. Алгоритм «вперед-назад».
- Лекция 4, Слайды 16-28
- вики
Алгоритм «вперёд-назад» -- алгоритм для вычисления апостериорных вероятностей последовательности состояний при наличии последовательности наблюдений. Или по другому, алгоритм для того, чтобы вычислить вероятность специфической последовательности наблюдений. Это работает в контексте скрытых Марковских моделей.
- работает за линейное по количеству наблюдаемых переменных (N)
Алгоритм включает три шага:
- вычисление прямых вероятностей
- вычисление обратных вероятностей
- вычисление сглаженных значений
[править] Метод релевантных векторов в задаче восстановления регрессии.
Лекция 5 Ветров.
[править] Метод релевантных векторов в задаче классификации.
Лекция 5 Ветров.
Еще слайды Ветрова, но не из этого круса от того более понятными не становятся
[править] Метод главных компонент.
Пусть имеется некоторая выборка 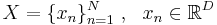 . Цель -- представить выборку в пространстве меньшей размерности d < D таким образом, чтобы в новом пространстве "схожие" объекты образовывали компактные области.
. Цель -- представить выборку в пространстве меньшей размерности d < D таким образом, чтобы в новом пространстве "схожие" объекты образовывали компактные области.
PCA (Principal Component Analysis) -- Метод главных компонент. Формулировки:
- проекция данных на гиперплоскость с наименьшей ошибкой проектирования
- поиск проекции на гиперплоскость с сохранением большей части дисперсии в данных
Википедия: Метод главных компонент
[править] Вероятностная формулировка метода главных компонент.
Метод главных компонент можно сформулировать в виде вероятностной модели со скрытыми переменными, для оптимизации которой используем метод максимального правдоподобия.
Преимущества:
- вычисление правдоподобия на тестовой выборке позволяет сравнивать различные вероятностные модели
- EM-алгоритм позволяет быстро находить решения в случае малого количества главных компонент
- EM-алгоритм позволяет избежать вычисление матрицы ковариации на промежуточном шаге
- возможность автоматического определения числа главных компонент
Вероятностная модель:
- Пусть имеется выборка
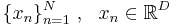
- для каждого объекта xn рассмотрим скрытую переменную
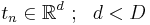
- определим распределение скрытых переменных
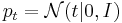 (многомерное нормальное распределение)
(многомерное нормальное распределение)
- Таким образом, модель наблюдаемой переменной x представляет собой линейное преобразование с добавлением гауссовского шума:
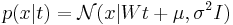 , где
, где
-
[править] ЕМ-алгоритм в методе главных компонент. Его преимущества.
[править] Метод главных компонент. Схема автоматического выбора числа главных компонент.
[править] Недостатки метода главных компонент. Метод независимых компонент.
Лекция 6, слайды 42-46
Недостатки метода главных компонент:
- возможны только линейные подпространства, объясняющие данные с высокой точностью. на практике часто такие поверхности могут быть сложными криволинейными.
- PCA инвариантен относительно поворота. это значит, что восстановление скрытых переменных неоднозначно. Это плохо в случае, если имеется несколько независимых источников, которые представимы линейной смесью с неизвестными коэффициентами
Метод независимых компонент -- направлен на разрешение второй проблемы PCO.
- пусть наблюдаемые переменные являются линейной комбинацией скрытых переменных, причем кол-во наблюдаемых и скрытых переменных совпадает: x = Wt
- если W невырождена, то t = W − 1x
Суть метода:
- рассматриваем отдельно каждый источник
- для каждого источника ищем ее, как линейную комбинацию наблюдаемых данных
- по Центральной предельной теореме сумма случайный величин приближается к нормальному распределению. А так как у нас не случайные величины, то нам нужно искать решение, которое меньше всего похоже на гауссиану
[править] Нелинейные методы уменьшения размерности. Локальное линейное погружение.
Лекция 6, слайды 48-50
PCA не позволяет находить преобразования, которые основаны на том факте, что близкие объекты на некоторой поверхности, были бы близки и в новом пространстве. то есть все наши наблюдения сосредотачиваются на некоторой (совсем не факт, что линейной) поверхности. Задача - восстановить эту поврехность
LLE ( локальное линейное погружение ) -- метод, основанный на поиске преобразования с учётом сохранения отношения соседства между объектами
[править] Нелинейные методы уменьшения размерности. Ассоциативные нейронные сети и GTM.
Лекция 6, слайды 51-55
[править] Часть 2 (Рудаков)
[править] Объекты, признаки, логические признаки, простейшие логические решающие правила.
Признаки объектов:
- детерминированные;
- вероятностные;
- логические;
- структурные.
Детерминированные признаки – это признаки, принимающие конкретные числовые значения, которые могут быть рассмотрены как координаты точки, соответствующей данному объекту, в n-мерном пространстве признаков.
Вероятностные признаки – это признаки, случайные значения которых распределены по всем классам объектов, при этом решение о принадлежности распознаваемого объекта к тому или другому классу может приниматься только на основании конкретных значений признаков данного объекта, определенных в результате проведения соответствующих опытов. Признаки распознаваемых объектов следует рассматривать как вероятностные и в случае, если измерение их числовых значений производится с такими ошибками, что по результатам измерний невозможно с полной определенностью сказать, какое числовое значение данная величина приняла.
Логические признаки распознаваемых объектов можно рассматривать как элементарные высказывания, принимающие два значения истинности (истина – ложь) с полной определенностью. К логическим признакам относятся прежде всего признаки, не имеющие количественного выражения. Эти признаки представляют собой суждения качественного характера типа наличия или отсутствия некоторых свойств или некоторых элементов у распознаваемых объектов или явлений. В качестве логических признаков можно рассматривать, например, такие симптомы в медицинской диагностике, как боль в горле, кашель и т.д. К логическим можно отнести также признаки, у которых важна не величина признака у распознаваемого объекта, а лишь факт попадания или непопадания ее в заданный интервал. В пределах этих интервалов появление различных значений признаков у распознаваемых объектов предполагается равновероятным. На практике логические признаки подобного рода имеют место в таких ситуациях, когда либо ошибками измерений можно пренебречь, либо интервалы значений признаков выбраны таким образом, что ошибки измерений практически не оказывают влияния на достоверность принимаемых решений относительно попадания измеряемой величины в заданный интервал.
Решающее правило
Decision Rule
В Data Mining это правила вида «Если …, то…», которые позволяют принять решение о принадлежности объекта или наблюдения к определенному классу, например, «Если ‘Годовой доход’ больше 200000, то ‘Кредитный рейтинг’ = ‘Высокий’. Основное применение решающих правил – деревья решений. В каждом узле дерева решений содержится решающее правило, разбивающее множество примеров в узле на подмножества, ассоциированные с классами.
Кроме этого, решающие правила применяются в методах покрытия, когда формируются наборы правил, которые последовательно относятся ко всем наблюдениям.
Остаток можно взять из файла lekcii_ama_zhuravlev.doc страница 17.
[править] Проблемы формирования логических признаков. Оценки качества признаков и их совокупностей.
Пусть 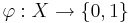 - некоторый предикат, определённый на множестве объектов X. Говорят, что предикат
- некоторый предикат, определённый на множестве объектов X. Говорят, что предикат 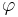 выделяет или покрывает (cover) объект x, если
выделяет или покрывает (cover) объект x, если
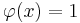 . Предикат называют закономерностью, если он выделяет достаточно много объектов какого-то одного класса c, и практически не выделяет объекты других классов.
. Предикат называют закономерностью, если он выделяет достаточно много объектов какого-то одного класса c, и практически не выделяет объекты других классов.
Пример: Решается вопрос о целесообразности хирургической операции. Закономерность: если возраст пациента выше 60 лет и ранее он перенёс инфаркт, то операцию не делать - риск отрицательного исхода велик.
Всякая закономерность классифицирует лишь некоторую часть объектов. Объединив определённое количество закономерностей в композицию, можно получить алгоритм, способный классифицировать любые объекты. Логическими алгоритмами классификации будем называть композиции легко интерпретируемых закономерностей. При построении логических алгоритмов возникают три основных вопроса:
- Каков критерий информативности, позволяющий называть предикаты закономерностями?
- Как строить закономерности?
- Как строить алгоритмы классификации на основе закономерностей? Наиболее распространённые типы логических алгоритмов: Голосование правил (алгоритм Кора), Алгоритмы вычисления оценок.
Теперь поговорим об информативности (или качестве) признака.
Своими словами: предикат тем более информативен, чем больше он выделяет объектов "своего класса" 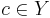 по сравнению с объектами всех остальных "чужих" классов. Свои объекты называют также позитивными (positive), а чужие негативными (negative). Введём следующие обозначения:
по сравнению с объектами всех остальных "чужих" классов. Свои объекты называют также позитивными (positive), а чужие негативными (negative). Введём следующие обозначения:
- Pc - число объектов класса c в выборке X
-
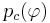 - из них число объектов, для которых выполняется условие ;
- из них число объектов, для которых выполняется условие ;
- Nc - число объектов всех остальных классов Y \ {c} в выборке X
-
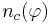 - из них число объектов, для которых выполняется условие
- из них число объектов, для которых выполняется условие
Введем ещё два обозначения:
-
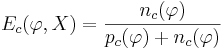 - доля негативных объектов среди всех выделяемых объектов (доля тех объектов, в которых наш логический предикат ошибся - причислил их к "своему" классу, хотя они туда и не относились)
- доля негативных объектов среди всех выделяемых объектов (доля тех объектов, в которых наш логический предикат ошибся - причислил их к "своему" классу, хотя они туда и не относились)
-
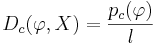 , где l есть это количество элементов в выборке X - это доля выделенных позитивных объектов.
, где l есть это количество элементов в выборке X - это доля выделенных позитивных объектов.
Существует несколько способов определения информативности: статическое определение, энтропийное. Также существует такое понятие как многоклассовая информативность, когда приходится оценивать информативность не только таких предикатов, которые отделяют один класс от остальных, но и таких, которые отделяют некоторую группу классов от остальных.
[править] Методы голосования по конъюнкциям. Алгоритмы типа "Кора".
Для начала, поговорим об алгоритмах голосования. Пусть для каждого класса построено множество логических закономерностей (правил), специализирующихся на различении объектов данного класса:
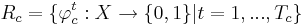 , где Tc - количество классов свойств.
, где Tc - количество классов свойств.
Считается, что если 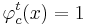 , то правило
, то правило 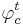 относит объект
относит объект 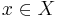 к классу c. Если же
к классу c. Если же 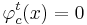 , то правило воздерживается от классификации объекта x.
, то правило воздерживается от классификации объекта x.
- Алгоритм простого голосования
- подсчитывает долю правил в наборах Rc, относящих объект x к каждому из классов:
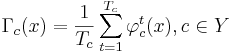
- относит объект x к тому классу, за который подана наибольшая доля голосов:
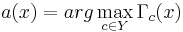
- если максимум достигается одновременно на нескольких классах, выбирается тот,
- подсчитывает долю правил в наборах Rc, относящих объект x к каждому из классов:
для которого цена ошибки меньше.
- Алгоритм взвешенного голосования
- Каждому правилу приписывается вес
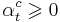
- при голосовании берётся взвешенная сумма голосов:
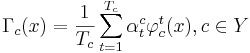
- веса принято нормировать на единицу:
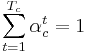
- Каждому правилу
При построении алгоритмов взвешенного голосования правил возникает четыре основных вопроса:
- Как построить много правил по одной и той же выборке?
- Как избежать повторов и построения почти одинаковых правил?
- Как избежать появления непокрытых объектов и обеспечить равномерное покрытие всей выборки правилами?
- Как определять веса правил при взвешенном голосовании?
Алгоритм Кора
- Дано
- множество элементарных предикатов Β
- обучающая выборка X
- Хотим получить
- набор конъюктивных закономерностей (т.е. множество конъюнкций элементарных предикатов Β, которые являлись бы закономерностями для нашей обучающей выборки X) ранга не более чем K (как правило берется число 3)
- доля ошибок
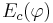 (см. предыдущий билет) для каждой из полученных конъюнкций не должна превышать Emax
(см. предыдущий билет) для каждой из полученных конъюнкций не должна превышать Emax
- доля позитивных объектов
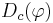 для каждой из полученных конъюнкций должна быть не меньше Dmin
для каждой из полученных конъюнкций должна быть не меньше Dmin
- Реализация
- перебираем все возможные конъюнкции ранга от 1 до K методом поиска в глубину:
- в процессе перебора:
- конъюнкция перестает наращиваться (и отбрасывается), если она выделяет слишком мало объектов своего класса, т.е.
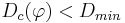
- конъюнкция перестает наращиваться (и запоминается), если она уже удовлетворяет критериям отбора, т.е.
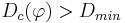 и
и 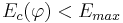
- конъюнкция перестает наращиваться (и отбрасывается), если она выделяет слишком мало объектов своего класса, т.е.
- Достоинства алгоритма
- Короткие конъюнкции легко интерпретируются в терминах предметной области. Алгоритм способен не только классифицировать объекты, но и объяснять свои решения на языке, понятном специалистам.
- При малых K (не больше 3) алгоритм очень эффективен
- Если короткие информативные конъюнкции существуют, они обязательно будут найдены, так как алгоритм осуществляет полный перебор.
- Недостатки алгоритма
- При неудачном выборе множества предикатов B коротких информативных конъюнкций может просто не существовать. В то же время, увеличение числа K приводит к экспоненциальному падению эффективности.
- Алгоритм не стремится обеспечивать равномерность покрытия объектов. Это отрицательно сказывается на обобщающей способности (вероятности ошибки) алгоритма.
Пример применения данного алгоритма - motp.pdf, страница 5
[править] Тесты, представительные наборы, проблемы перебора.
Матрица эталонов Tnmi: Каждый столбец соответсвует определенному признаку. Каждая строка - эталонному объекту. Последовательно идущий набор строк - определяет класс.
Подмножество столбцов матрицы эталонов называется тестом, если в подтаблице, образованной данным подмножеством столбцов, все строки, относящиеся к разным классам, различны.
Тупиковый тест - минимальная подсистема признаков(столбцов), разделяющая эталонные объекты разных классов.
Пример - алгоритм Кора, файл motp.pdf 5 страница. Фактически, характеристики классов строятся при помощи тестов.
Пусть объект 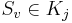 . Набор признаков
. Набор признаков 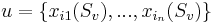 называется ε-представительским (или просто представительским), если
называется ε-представительским (или просто представительским), если 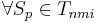 и не лежащих в классе Kj система неравенств
и не лежащих в классе Kj система неравенств 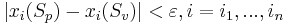 несовместна.
несовместна.
Существуют эффективные алгоритмы поиска тупиковых тестов. Тем не менее, задача нахождения множества всех тупиковых тестов является вычислительно сложной комбинаторной задачей и не может быть решена на современных компьютерах даже для относительно небольших таблиц обучения (сотни объектов и признаков). Поэтому при решении практических задач вычисляют и используют в процедурах голосования обычно лишь часть тупиковых тестов.
[править] Пространства объектов для АВО. Обучающие и контрольные объекты. Метрические описания объектов в АВО.
Алгоритмы вычисления оценок
Дано:
-
![S = \{s_i\},~~ i \in [1, m]](/w/images/math/6/a/e/6ae9cd5ce490ffa2ac31d8aaf958460a.png) -- множество объектов. обучающая выборка
-- множество объектов. обучающая выборка
-
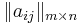 -- совокупность из m объектов, каждый из n признаки
-- совокупность из m объектов, каждый из n признаки
- области определения признаков -- метрические пространства Mt с метриками
![\rho_t:M^2_t \rightarrow \mathbb{R^+},~~ t \in [1, n]](/w/images/math/b/f/b/bfb79b96b10e3494d1b70acfcf4ffc66.png)
-
![K = \{K_i\}~,~~i \in [1, l]](/w/images/math/b/5/2/b52fb2c688c21cf6701c42186edbabee.png) -- можество классов, на которые разделяются объекты
-- можество классов, на которые разделяются объекты
-
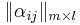 -- информационная матрица (таблица), с указанием того, какой из каждых m объектов каким классам принадлежит
-- информационная матрица (таблица), с указанием того, какой из каждых m объектов каким классам принадлежит
Описание класса -- список объектов из обучающей выборки, которые входят в класс, и список тех, которые не входят
Контрольная выборка -- набор из q объектов, предназначенных для определения разных параметров алгоритма:
-
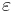 -- параметры близости
-- параметры близости
- {Ω} -- опорные множества
- pw -- веса опорных множеств
- x1,x2 -- коэффициентов для формулы вычисления оценок
- γj -- веса обучающих объектов
Так как пространство признаков не обязательно является числовым, то имеет смысл задавать объект через меры близости к объектам обучающей выборки (метрическое описание объектов) : 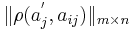 , где
, где
-
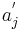 -- j-тый признак описываемого объект
-- j-тый признак описываемого объект
- aij -- j-тый признак i-того объекта базовой выборки S
[править] Опорные множества в АВО. Функции близости. Веса объектов и признаков.
Система опорных множеств -- любое множество, элементы которого - непустые подмножества признаков {1,2...n}. При этом каждый признак должен входить хотя бы в одно множество:
-
![\{\Omega\}_A ~ : ~ \Omega_j = \{u_1, u_2, \dots, u_k\},~ u_k \in [1,n]](/w/images/math/b/c/8/bc867411cf74b986737d0f719bda673f.png) -- совокупность опорных множеств, задающих алгоритм распознавания A
-- совокупность опорных множеств, задающих алгоритм распознавания A
-
![\forall i \in [1,k] ~~ \exists j : i \in \Omega_j](/w/images/math/9/8/b/98bb7331a55658d004b0038808a8675c.png) , каждый признак хотя бы в одном опорном множестве.
, каждый признак хотя бы в одном опорном множестве.
- вместо Ωj можем рассматривать характеристический вектор
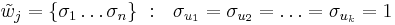 , а остальные координаты равны нулю
, а остальные координаты равны нулю
Примеры опорных множеств:
- совокупность всех непустых подмножеств признаков {1,2...n}. его мощность: 2n − 1
- совокупность из всех подмножеств из k элементов. его мощность:
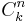
Функция близости 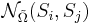 -- задает расстояние между проекциями объектов Si и Sj на
-- задает расстояние между проекциями объектов Si и Sj на 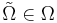 . В дальнейшем рассматриваются только такие функции
. В дальнейшем рассматриваются только такие функции 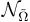 , которые принимают значения 0 или 1 (бинарные).
, которые принимают значения 0 или 1 (бинарные).
Три вида функции близости:
- Введем неотрицательные параметры
![\varepsilon_i > 0 ~,~ i \in [1,n]](/w/images/math/d/a/4/da4b0a3bf47a931a6a408b710cecb80a.png) . Пусть
. Пусть 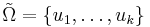 . Тогда
. Тогда ![\mathcal{N}_{\tilde\Omega}(S_i, S_j) =
\begin{cases}
1,~~\rho(\alpha_{i,u_l}, \alpha_{j,u_l}) \leqslant \varepsilon_{u_l}~~\forall l \in [1,k]\\
0,~~otherwise
\end{cases}](/w/images/math/3/5/e/35ecba6a21bb1f70b8a7eb6cd09abedb.png)
- Введем дополнительно к п.1 параметр ν такой, что функция близости будет определятся как
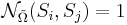 , если не выполнено не больше, чем ν описанных неравенств. при этом имеет смысл брать
, если не выполнено не больше, чем ν описанных неравенств. при этом имеет смысл брать ![0 \leqslant \nu \leqslant \left[\frac{k}{2} - 1\right]](/w/images/math/5/e/d/5edb55f453ba1d1f204a86c10e8734cd.png)
- Вместо ν определяем ν' и функцию близости так, что , если из k неравенств не выполнены r, причем
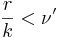
- К билету был вопрос: какие сколько возможных выборок
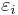 стоит рассматривать. Вообще говоря -действительно так-что континуум. Но смысл будут нести только l*m*n вариантов. где l - число признаков(колчисетво этих ),m - число компонент обучающей выборки, n - число компонент контрольной выборки. Другими словами мы задаем какое хотим, но обычно его задают между значениями признаков на выборке, при этом всего у нас m*n сравнений и таким образом m*n вариантов его задать(для одного )
стоит рассматривать. Вообще говоря -действительно так-что континуум. Но смысл будут нести только l*m*n вариантов. где l - число признаков(колчисетво этих ),m - число компонент обучающей выборки, n - число компонент контрольной выборки. Другими словами мы задаем какое хотим, но обычно его задают между значениями признаков на выборке, при этом всего у нас m*n сравнений и таким образом m*n вариантов его задать(для одного )
[править] Формулы вычисления оценок. Эвристические обоснования.
Формула вычисления оценок:
 , где:
, где:
- -- опорные множества
- Pj(Sk) = 1 если объект Sk входит в класс j.
- γk -- вес объекта Sk.
-
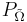 -- вес опорного множества.
-- вес опорного множества.
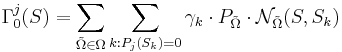 , где:
, где:
- Pj(Sk) = 0 если объект Sk не входит в класс j.
Итоговая формула для оценки принадлежности объекта S классу j:
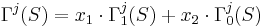 , где x1,x2 -- коэффициенты, которые определяют работу с соответствующими характеристиками.
, где x1,x2 -- коэффициенты, которые определяют работу с соответствующими характеристиками.
[править] Задачи оптимизации АВО. Совместные подсистемы систем неравенств.
[править] Функционалы качества. Сложность моделей алгоритмов и проблема переобучения.
Функционал качества алгоритма. Пусть задана таблица контрольных объектов (множество объектов, на которых мы будет проверять качество работы нашего алгоритма распознавания). Для контрольных объектов мы должны знать, к какому классу свойств относится каждый из объектов (иначе как мы будет проверять корректность работы нашего алгоритма). Подаем контрольные объекты на вход алгоритму. Доля правильных ответов, выданных алгоритмов - это и есть функционал качества (в простейшем случае).
Обобщающая способность (generalization ability, generalization performance). Говорят, что алгоритм обучения обладает способностью к обобщению, если вероятность ошибки на тестовой выборке достаточно мала или хотя бы предсказуема, то есть не сильно отличается от ошибки на обучающей выборке. Обобщающая способность тесно связана с понятиями переобучения и недообучения.
Переобучение, переподгонка (overtraining, overfitting) — нежелательное явление, возникающее при решении задач обучения по прецедентам, когда вероятность ошибки обученного алгоритма на объектах тестовой выборки оказывается существенно выше, чем средняя ошибка на обучающей выборке. Переобучение возникает при использовании избыточно сложных моделей.
Недообучение — нежелательное явление, возникающее при решении задач обучения по прецедентам, когда алгоритм обучения не обеспечивает достаточно малой величины средней ошибки на обучающей выборке. Недообучение возникает при использовании недостаточно сложных моделей.
[править] Общие пространства начальных и финальных информаций. Задачи синтеза корректных алгоритмов.
Диссертация Рудакова, пункт 1.1
В самой общей постановке задача синтеза алгоритмов преобразования информаций состоит в следующем. Имеется множество начальных информаций  и множество конечных информаций
и множество конечных информаций  . Требуется построить алгоритм реализующий отображение из в , удовлетворяющее заданной системе ограничений.
. Требуется построить алгоритм реализующий отображение из в , удовлетворяющее заданной системе ограничений.
Одним из частных случаев является задача обучения по прецедентам, в которой система ограничений задаётся следующим образом. Фиксируется последовательность 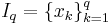 элементов множества и последовательность
элементов множества и последовательность 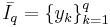 элементов множества . Искомый алгоритм A должен точно или приближённо удовлетворять системе из q равенств
элементов множества . Искомый алгоритм A должен точно или приближённо удовлетворять системе из q равенств 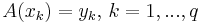 , которую мы будем сокращённо записывать как
, которую мы будем сокращённо записывать как 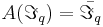 . Ограничения такого типа называются локальными или прецедентными.
. Ограничения такого типа называются локальными или прецедентными.
Кроме того,обычно требуется, чтобы искомый алгоритм удовлетворял некоторым дополнительным ограничениям, которые в общем случае выражаются условием 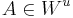 где Wu заданное множество отображений из в . Алгоритм, удовлетворяющий локальным и дополнительным ограничениям, называют корректным. Итак, рассматриваемые задачи обучения по прецедентам определяется пятёркой
где Wu заданное множество отображений из в . Алгоритм, удовлетворяющий локальным и дополнительным ограничениям, называют корректным. Итак, рассматриваемые задачи обучения по прецедентам определяется пятёркой 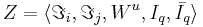 .
.
Различие между локальными и дополнительными ограничениями заключается в том, что первые относятся к конечному набору точек и допускают эффективную проверку, в то время как вторые накладываются на всёотображение «в целом» и не допускают эффективной проверки. В частности, это могут быть ограничения непрерывности, гладкости, монотонности, унимодальности, и т. д. На практике дополнительные ограничения учитываются на этапе построения параметрического семейства алгоритмов,а локальные при последующей настройке параметров алгоритма на заданные прецеденты
[править] Разрешимость и регулярность задач распознавания. Регулярность по Ю.И. Журавлёву
Диссертация Рудакова, пункт 1.5
Разрешимые задачи - это задачи, для которых множество допустимых отображений их  в
в  непусто, т.е. существуют семейства алгоритмов, содержащие их решения.
Задача Z из множества задач
непусто, т.е. существуют семейства алгоритмов, содержащие их решения.
Задача Z из множества задач 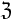 называется полной относительно семейства
называется полной относительно семейства 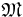 отображений из в , если в содержатся допустимые отображения для всех задач из класса эквивалентности, содержащего Z.
Задача Z называется регулярной, если для нее существует семейство отображений , относительно которого она полна.
отображений из в , если в содержатся допустимые отображения для всех задач из класса эквивалентности, содержащего Z.
Задача Z называется регулярной, если для нее существует семейство отображений , относительно которого она полна.
Регулярность по Журавлеву:
Пусть есть q объектов и l классов и
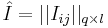 - матрица информации и
- матрица информации и 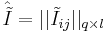 - матрица правильных ответов.
Задаче Z соответствует пара матриц:
- матрица правильных ответов.
Задаче Z соответствует пара матриц: 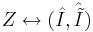 .
Определение окрестности задачи по Журавлеву
.
Определение окрестности задачи по Журавлеву 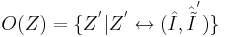 - т.е. это множество задач Z', получающихся всевозможным варьированием матрицы правильных ответов.
- т.е. это множество задач Z', получающихся всевозможным варьированием матрицы правильных ответов.
- Разбиваем множество задач на классы эквивалентности. Задача называется регулярной если она разрешима и разрешимы все задачи из класса эквивалентности который она порождает.
[править] Операции над алгоритмами. Расширение моделей.
http://www.ict.edu.ru/ft/004700/VoronCanDisser.pdf
Пункт 1.2
[править] Пространства оценок. Алгоритмы как суперпозиции.
http://www.ict.edu.ru/ft/004700/VoronCanDisser.pdf
Пункт 1.2
[править] Понятие полноты моделей алгоритмов и семейств корректирующих операций.
Диссертация Рудакова 1.3 + 1.5 пункты. Диссертация Рудакова, пункт 3.5
Модель алгоритмов категории Φ0 называется полной, если любая регулярная задача Z из множества ![\mathfrak{Z}_{[R]}](/w/images/math/9/6/b/96bc93a1024d4c815c3b61492beb53ef.png) полна относительно , т.е. если для любой регулярной задачи Z модель алгоритмов от любой матрицы исходных информаций этой задачи приводит в множество конечных информаций.
(т.е. в модели алгоритмов для каждой регулярной задачи из множества содержится корректный алгоритм)
полна относительно , т.е. если для любой регулярной задачи Z модель алгоритмов от любой матрицы исходных информаций этой задачи приводит в множество конечных информаций.
(т.е. в модели алгоритмов для каждой регулярной задачи из множества содержится корректный алгоритм)
[править] Дополнительные к прецедентам ограничения. Пример: перестановочность строк и столбцов в матрицах информации.
Прецедентная (локальная) информация - описания объектов и данные о принадлежности объектов к классам. Дополнительные к прецедентным (универсальные) ограничения - формальные ограничения на вид допустимых отображений.
[править] Задачи с однородными классами
Пусть рассматривается задача, в которой имеется информация о том, что порядок, в котором анализируются классы несущественен, и кроме прецедентных данных нет сведений о различии классов. Универсальные ограничения, выражающие однородность классов, состоят в том, что отображение, реализуемое корректным алгоритмом, должно коммутировать со всеми подстановками столбцов (при любой перстановке столбцов в матрице информации точно так же должны переставляться столбцы в матрице, порожденной алгоритмом).
[править] Задачи с непересекающимися классами.
Диссертация Рудакова, пункт 2.5
[править] Класс поэлементных операций и отображений. Условия регулярности и полноты.
[править] Полнота моделей АВО.
Диссертация Рудакова, пункт 3.5
[править] Полнота полиномиальных семейств корректирующих операций.
Корректирующие операции по сути - операции над матрицами. Один из самых мощных и применяемых на практике - корректирующие полиномы некоторой степени, от матриц с Адамаровым умножением.
Основной вопрос - степень полинома, который может задать любую матрицу (и обеспечить таки образом полноту системы корректирующих операций). Было доказано, что при размерах матрицы информации q * l, система из полиномов степени q * l − 1 - полна, q * l − 2 - не полна.
[править] Логарифмическая граница степени корректирующих полиномов.
Для частного случая - матрицы информации, состоящие из нулей и единиц, оценку степени корректирующих полиномов удалось улучшить. Для таких полиномов степень может быть снижена до 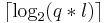
Полезная информация к билету из Диссертации Рудакова
- Определение корректирующих операций - п. 1.3 стр 27
- Полнота полиномиальных семейств к.о. - п. 5.6 стр 116
- Определение 0,1-полноты - определение 6.1.2 стр 119
- Теорема о логарифмической границе степени корректирующих полиномов - теорема 6.1.3, стр 120
Математические основы теории прогнозирования
Материалы по курсу
Билеты (2009) | Примеры задач (2009) | Примеры задач контрольной работы (2013) | Определения из теории вероятностей


